Go 语言底层剖析
GMP
数据结构
- G — 表示 Goroutine,它是一个待执行的任务;
- M — 表示操作系统的线程,它由操作系统的调度器调度和管理;
- P — 表示处理器,它可以被看做运行在线程上的本地调度器;
我们先在这里介绍一下不同的数据结构, 作用以及运行期间可能的状态: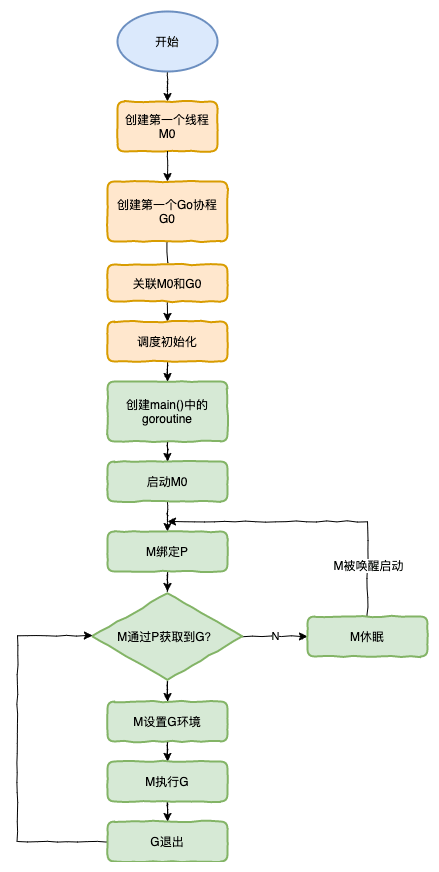
G
Goroutine 是 Go 语言调度器中待执行的任务,它在运行时调度器中的地位与线程在操作系统中差不多,但是它占用了更小的内存空间,也降低了上下文切换的开销。
Goroutine只存在于Go语言的运行时,它是Go语言在用户态提供的线程,作为粒度更细的资源调度单元,如果使用得当能够在高并发的场景下更高效地利用机器的CPU.
Goroutine在Go语言运行时使用私有结构体runtime.g来表示,这个私有结构体十分复杂,里也不会介绍所有的字段,仅会挑选其中的一部分,首先是与栈相关的两个字段:
type g struct {
stack stack
stackguard0 uintptr
}
stack字段保存了当前goroutine1的栈内存范围[stack.lo, stack.hi], 另一个字段stackguard0可以用于调度器抢占式调度.除了stackguard0外,goroutine还包含了另外三个与抢占密切相关的字段,
type g struct {
preempt bool // 抢占信号
preemptStop bool // 抢占时将状态修改成 `_Gpreempted`
preemptShrink bool // 在同步安全点收缩栈
}
Goroutine 与我们在前面章节提到的 defer 和 panic 也有千丝万缕的联系,每一个 Goroutine 上都持有两个分别存储 defer 和 panic 对应结构体的链表:
type g struct {
_panic *_panic // 最内侧的 panic 结构体
_defer *_defer // 最内侧的延迟函数结构体
}
最后,我们再节选一些作者认为比较有趣或者重要的字段:
type g struct {
m *m // m是当前goroutine抢占的线程
sched gobuf // 存储goroutine调度相关的数据
atomicstatus uint32 // goroutine的状态
goid int64 // goroutine的id
}
上述四个字段中,我们需要展开介绍 sched 字段的 runtime.gobuf 结构体中包含哪些内容:
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ret sys.Uintreg
...
}
sp — 栈指针;
pc — 程序计数器;
g — 持有 runtime.gobuf 的 Goroutine;
ret — 系统调用的返回值;
这些内容会在调度器保存或者恢复上下文的时候用到,其中的栈指针和程序计数器会用来存储或者恢复寄存器中的值,改变程序即将执行的代码。
结构体 runtime.g 的 atomicstatus 字段存储了当前 Goroutine 的状态。除了几个已经不被使用的以及与 GC 相关的状态之外,Goroutine 可能处于以下 9 种状态:
| 状态 | 描述 |
|---|---|
| _Gidle | 刚刚被分配并且还没有被初始化 |
| _Grunnable | 没有执行代码,没有栈的所有权,存储在运行队列中 |
| _Grunning | 可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P |
| _Gsyscall | 正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上 |
| _Gwaiting | 由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上 |
| _Gdead | 没有被使用,没有执行代码,可能有分配的栈 |
| _Gcopystack | 栈正在被拷贝,没有执行代码,不在运行队列上 |
| _Gpreempted | 由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒 |
| _Gscan | GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在 |
虽然 Goroutine 在运行时中定义的状态非常多而且复杂,但是我们可以将这些不同的状态聚合成三种:等待中、可运行、运行中,运行期间会在这三种状态来回切换:
- 等待中:Goroutine 正在等待某些条件满足,例如:系统调用结束等,包括 _Gwaiting、_Gsyscall 和 _Gpreempted 几个状态;
- 可运行:Goroutine 已经准备就绪,可以在线程运行,如果当前程序中有非常多的 Goroutine,每个 Goroutine 就可能会等待更多的时间,即 _Grunnable;
- 运行中:Goroutine 正在某个线程上运行,即 _Grunning;
M
M是操作系统的线程,调度器最多可以创建10000个线程,但是其中大多数线程都不会执行用户代码,最多只有GOMAXPROCS个活跃的线程能正常运行.
在默认情况下,运行时将GOMAXPROCS设置成当前机器的核数,我们也可以在程序中使用runtime.GOMAXPROCS来修改.
Go 语言会使用私有结构体 runtime.m 表示操作系统线程,这个结构体也包含了几十个字段,这里先来了解几个与 Goroutine 相关的字段:
type m struct {
// g0是持有调度栈的Goroutine,curg是当前线程上运行的用户Goroutine,也是操作系统线程唯一关心的两个Goroutine
g0 *g
curg *g
...
}
g0 是一个运行时中比较特殊的 Goroutine,它会深度参与运行时的调度过程,包括 Goroutine 的创建、大内存分配和 CGO 函数的执行。在后面的小节中,我们会经常看到 g0 的身影。
M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
G0 是每次启动一个 M 都会第一个创建的 goroutine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
P
调度器中的处理器 P 是线程和 Goroutine 的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列,通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的利用率。
因为调度器在启动时就会创建 GOMAXPROCS 个处理器,所以 Go 语言程序的处理器数量一定会等于 GOMAXPROCS,这些处理器会绑定到不同的内核线程上。
runtime.p 是处理器的运行时表示,作为调度器的内部实现,它包含的字段也非常多,其中包括与性能追踪、垃圾回收和计时器相关的字段,这些字段也非常重要,但是在这里就不展示了,我们主要关注处理器中的线程和运行队列:
type p struct {
m muintptr
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
...
}
反向存储的线程维护着线程与处理器之间的关系,而 runqhead、runqtail 和 runq 三个字段表示处理器持有的运行队列,其中存储着待执行的 Goroutine 列表,runnext 中是线程下一个需要执行的 Goroutine。
runtime.的state字段会是下面:
| 状态 | 描述 |
|---|---|
| _Pidle | 处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空 |
| _Prunning | 被线程 M 持有,并且正在执行用户代码或者调度器 |
| _Psyscall | 没有执行用户代码,当前线程陷入系统调用 |
| _Pgcstop | 被线程 M 持有,当前处理器由于垃圾回收被停止 |
| _Pdead | 当前处理器已经不被使用 |
调度器启动
调度器的启动过程是我们平时比较难以接触的过程,不过作为程序启动前的准备工作,理解调度器的启动过程对我们理解调度器的实现原理很有帮助,运行时通过 runtime.schedinit 初始化调度器:
在调度器初始函数执行的过程中会将 maxmcount 设置成 10000,这也就是一个 Go 语言程序能够创建的最大线程数,虽然最多可以创建 10000 个线程,但是可以同时运行的线程还是由 GOMAXPROCS 变量控制。
我们从环境变量 GOMAXPROCS 获取了程序能够同时运行的最大处理器数之后就会调用 runtime.procresize 更新程序中处理器的数量,在这时整个程序不会执行任何用户 Goroutine,调度器也会进入锁定状态
创建 Goroutine
想要启动一个新的 Goroutine 来执行任务时,我们需要使用 Go语言的 go 关键字,编译器会通过 cmd/compile/internal/gc.state.stmt 和 cmd/compile/internal/gc.state.call 两个方法将该关键字转换成 runtime.newproc 函数调用:
runtime.newproc 的入参是参数大小和表示函数的指针 funcval,它会获取 Goroutine 以及调用方的程序计数器,然后调用 runtime.newproc1 函数获取新的 Goroutine 结构体、将其加入处理器的运行队列并在满足条件时调用 runtime.wakep 唤醒新的处理执行 Goroutine:
runtime.newproc1 会根据传入参数初始化一个 g 结构体:
- 获取或者创建新的 Goroutine 结构体;
- 将传入的参数移到 Goroutine 的栈上;
- 更新 Goroutine 调度相关的属性;
调度
这是本章的重点,分为 调度策略 和 调度时机 。
调度策略
即从哪里获取 协程?下面是调度策略函数:
主要的调度逻辑就是这三段
第一段主要是防止 全局协程队列 中的协程等待太久,那么每执行 61 次 本地协程队列中的协程调度(常量竟然是写死的 -_-!!!),就从 全局协程队列 获取一个 G 放到 P的本地协程队列 中 (runqput 函数) 那么一开始肯定不会进入这里。
所以一开始的入口是第二段, 直接从本地协程队列获取协程。
然后就是 进入到真正策略函数 findrunnable 。
进入findrunnable 可以看到 一开始 也是通过 runqget 获取 p 的本地协程队列
P 本地协程队列
进入findrunnable 可以看到 一开始 也是通过 runqget 获取 p 的本地协程队列 它的处理逻辑也很简单,流程是:
先返回 p.next 指向的协程, 如果 next==0 就从 q.runq 本地协程队列获取协程返回。
其中可以看到如果 head == tail 则表示队列为空。
然后是 globrunqget方法 获取 len(p.runq) / 2 数量的 goroutine,放到 p 的本地协程队列中(runqput)
获取准备就绪的网络协程
然后就是 获取准备就绪的网络协程:
如果有网络协程,则在 injectglist函数中, 将 所有网络协程 通过 globrunqputbatch方法 都加入到全局协程队列中。
窃取其他P中的G
最后从其他 P中窃取G
进入 stealWork 可以看到, 所有的 p 都在一个 allp []*p 的全局变量中。
通过一个算法(有兴趣的朋友可以自行研究一下,这里就不详解了),保证了一定会遍历 allp 中的所有元素。
然后在在 runqsteal() 调用 runqgrab() 窃取别的 P 中一半协程 到自己的本地协程队列中。
执行
schedule() 方法 的最后,就是调用 execute()方法 :
将 g 状态改为 _Grunnable -> _Grunning
最后通过 gogo 将 Goroutine 调度到当前线程上执行,gogo 在不同的处理器架构上实现方式不一样(汇编),最终都会调用 goexit0() 方法 :
// goexit continuation on g0.
func goexit0(gp *g) {
...
casgstatus(gp, _Grunning, _Gdead)
...
gfput(_g_.m.p.ptr(), gp)
...
schedule()
}
其中主要的逻辑就是:
将 goroutine 变成 _Gdead 状态,然后通过 gfput 将 goroutine 放入P 的 gFree list然后重新调度
如果 p 中 gFree list 中 协程的数量 >= 64, 就弹出一半加入到全局协程回收站中 sched.gFree
调度时机
因为调度器的 schedule会重新选择 Goroutine 在线程上执行,所以我们只要找到该函数的调用方就能找到所有触发调度的时间点。
整理如下:
mstart1(): 线程启动
Goexit() -> goexit1() ->goexit0(): 协程退出
Gosched() -> `gosched_m() -> goschedImpl(): 主动让出
gopark() -> park_m() : 被动等待
exitsyscall() -> exitsyscall0(): 退出系统调用
preemptPark(): 抢占p
startTheWorld() -> semrelease1() -> goyield() -> goyield_m(): gc
协程退出 在上一节 执行 中已经说了,这里就不重复。
线程启动 主要是初始化 P,比较简单,这里就不叙述了,感兴趣的朋友可以自己了解一下。
剩下的,我们再一个一个来看。
抢占 P 咱们单独拿一节来说。
主动让出
有时候我们会主动调用 runtime.Gosched() 让出 goroutine 的 cpu 执行。比如自旋锁的实现,如果我们发现锁被占用,就直接让出 cpu:
逻辑也比较简单:
将 goroutine 状态从 _Grunning 变成 _Grunnable通过 dropg 将 m 与 goroutine 解绑再将 goroutine 放入 全局 grouting 队列开始新一轮调度
被动等待:
这是最常见的,比如 网络I/O、chan 阻塞、定时器 等都会进入这里面。
总的逻辑也比较简单:
将 goroutine 状态从 _Grunning 变成 _Gwaiting通过 dropg 将 m 与 goroutine 解绑重新调度
等待被唤醒
运行时通过 goready() 唤醒等待的 goroutine, 核心逻辑在 ready() 中,逻辑也很简单: 修改 g 的状态 _Gwaiting -> _Grunnable放入本地队列
退出系统调用
系统调用前,运行时会调用 reentersyscall()。它会完成 Goroutine 进入系统调用前的准备工作:
保存当前 PC 和栈指针 SP 中的内容修改 g 的状态 _Grunning -> _Gsyscall;修改 p 的状态为 _Psyscall并解除 p 与 m 之间的绑定将 P 放入 oldp 中
然后就是进入系统调用。
当系统调用结束后,会调用退出系统调用的函数,将 g 重新执行:
这里有一个快速路径和一个慢的路径。
跳进 exitsyscallfast() 逻辑可以看到: 快路径就是获取当前 g,然后将 g 与 oldp (即进入系统调用时候保存的 p)进行绑定:
执行从注释就能看出来:
如果获取到空闲 p,就直接绑定 p 和 m, 然后执行当前。
如果获取不到,就将当前 g 状态改为 _Grunnable ,放进全局协程队列,执行。
startTheWorld
逻辑也非常简单:
修改协程状态 _Grunning -> _Grunnable将 g 与 m 解绑重新放入当前 p 的本地队列重新调度
从中可以看到,当 p 在 _Prunning 或 _Psyscall 状态下,有 5种情况 p 会被抢占
如果 p 距离上次调度已经过去 10us (pd.schedwhen+forcePreemptNS <= now)如果系统调用超过了一个 sysmon tick (20us)系统调用情况下,p 中的本地 goroutine 队列中有等待运行的G(runqempty(p))。 这时候抢占只是为了让本地队列中的 goroutine有执行的机会。没有空闲 p 和 自旋的 m ( atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 )。有的话,说们很闲,抢占了也没有意义当系统调用时间超过了 10us (pd.syscallwhen+1010001000)
总结
一开始我们介绍了 GMP 结构体中重要字段的意思。
然后就是重点 调度 ,调度可以看作是一个死循环,分为 调度策略 和 调度时机
调度策略逻辑如下:
先从 p 的 本地协程队列 获取 g,如果没有,就从全局协程队列里,获取第一个,然后拿一部分协程(最多拿走 256/2 个) 到本地中;
如果 全局队列 中没有, 就获取将网络协程中的第一个,然后将剩下的所有网络协程都加入到全局协程队列中。
如果还是没有, 就从其他 p 的本地协程队列中 窃取一半 到自己本地队列中。
然后就是调度时机,常见的就是:
主动让出:
runtime.Gosched() 。协程状态 _Grunnable 变成 _Grunning ,放入全局协程队列。
- 被动等待:
网络I/O、channel、定时器;将协程状态从 _Grunning 变成 _Gwaiting,然后与 m 解绑。
唤醒后,将协程状态从 _Gwaiting 变成 _Grunnable,然后放入当前 p 的本地协程队列。
3.退出系统调用
退出后就要要么马上执行当前 goroutine(快路径);
要么就是慢路径: 将协程状态从 _Gwaiting 变成 _Grunnable,然后放入当前 p 的全局协程队列。。
- gc 的 stop the world 后的 start the world:
修改协程状态 _Grunning -> _Grunnable; 将 g 与 m 解绑; 重新放入当前 p 的本地队列
最后就是,就是监控线程的抢占 p ,它的目的主要是为了更公平是实现调度,防止其他 协程出现饥饿的情况。主要是出现下面两种情况会发生抢占:
超过了系统 tick(即20微秒)当前执行超过了 10 微秒(系统执行或者用户协程执行)
然后将当前的 g 放入全局队列
参考<https://zhuanlan.zhihu.com/p/502740833>
Chan 底层
设计原理
Go语言最常见的也是经常被人提及的设计模式是:不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存。在很多主流的编程语言中,多个线程传递数据的方式一般都是共享内存,为了解决线程竞争,我们需要限制同一时间能够读写这些变量的线程数量,然而这与 Go 语言鼓励的设计并不相同。
虽然我们在 Go 语言中也能使用共享内存加互斥锁进行通信,但是 Go 语言提供了一种不同的并发模型,即通信顺序进程(CSP), Goroutine 和 Channel 分别对应 CSP 中的实体和传递信息的媒介,Goroutine 之间会通过 Channel 传递数据。
先入先出
目前的 Channel 收发操作均遵循了先进先出的设计,具体规则如下:
- 先从 Channel 读取数据的 Goroutine 会先接收到数据;
- 先向 Channel 发送数据的 Goroutine 会得到先发送数据的权利;
这种 FIFO 的设计是相对好理解的,但是稍早的 Go 语言实现却没有严格遵循这一语义...
数据结构
Go语言的Channel在运行时使用runtime.hchan结构体表示,我们在Go语言中创建新的Channel时,实际上创建的是如下的结构体:
type hchan struct {
qcount uint // Channel元素的个数
dataqsiz uint // Channel 中的循环队列的长度
buf unsafe.Pointer // Channel 的缓冲区数据指针;
elemsize uint16 // 能够接收的大小
closed uint32
elemtype *_type // 能够接收的类型
sendx uint // Channel 的发送操作处理到的位置;
recvx uint // Channel 的接收操作处理到的位置;
recvq waitq // 存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表
sendq waitq // 存储了当前 Channel 由于接收空间不足而阻塞的 Goroutine 列表
lock mutex
}
// 这些等待队列使用双向链表 runtime.waitq 表示,链表中所有的元素都是 runtime.sudog 结构:
type waitq struct {
first *sudog
last *sudog
}
创建管道
Go语言创建管道使用make关键词,这一阶段会对传入 make 关键字的缓冲区大小进行检查,如果我们不向 make 传递表示缓冲区大小的参数,那么就会设置一个默认值 0,也就是当前的 Channel 不存在缓冲区。
这一阶段根据传入chan的缓冲区大小有所不同:
- 如果当前chan不存在缓冲区,则只为runtime.hchan分配一段内存空间
- 如果当前chan中存储的类型不是指针类型,会为当前的 Channel 和底层的数组分配一块连续的内存空间;
- 在默认情况下会单独为 runtime.hchan 和缓冲区分配内存;
发送数据
当我们想要向 Channel 发送数据时,就需要使用 ch <- i 语句
发送数据时会调用runtime.chansend,这个函数包含了发送数据的全部逻辑,如果我们在调用时将block参数设置为true,那么表示当前的发送操作是阻塞的.在发送数据的逻辑执行之前会为当前Channel加锁,防止多线程并发修改数据,如果channel已经关闭则会panic.
因为 runtime.chansend 函数的实现比较复杂,所以我们这里将该函数的执行过程分成以下的三个部分:
- 当存在等待的接收者时,通过 runtime.send 直接将数据发送给阻塞的接收者;
- 当缓冲区存在空余空间时,将发送的数据写入 Channel 的缓冲区;
- 当不存在缓冲区或者缓冲区已满时,等待其他 Goroutine 从 Channel 接收数据;
发送数据时会调用 runtime.send,该函数的执行可以分成两个部分:
- 调用 runtime.sendDirect 将发送的数据直接拷贝到 x = <-c 表达式中变量 x 所在的内存地址上;
- 调用 runtime.goready 将等待接收数据的 Goroutine 标记成可运行状态 Grunnable 并把该 Goroutine 放到发送方所在的处理器的 runnext 上等待执行,该处理器在下一次调度时会立刻唤醒数据的接收方;
缓冲区
如果创建的 Channel 包含缓冲区并且 Channel 中的数据没有装满,在这里我们首先会使用 runtime.chanbuf 计算出下一个可以存储数据的位置,然后通过 runtime.typedmemmove 将发送的数据拷贝到缓冲区中并增加 sendx 索引和 qcount 计数器。
阻塞发送
当 Channel 没有接收者能够处理数据时,向 Channel 发送数据会被下游阻塞,当然使用 select 关键字可以向 Channel 非阻塞地发送消息。向 Channel 阻塞地发送数据时会:
- 获取发送数据的Goroutine
- 执行 runtime.acquireSudog 获取 runtime.sudog 结构并设置这一次阻塞发送的相关信息,例如发送的 Channel、是否在 select 中和待发送数据的内存地址等;
- 将刚刚创建并初始化的 runtime.sudog 加入发送等待队列,并设置到当前 Goroutine 的 waiting 上,表示 Goroutine 正在等待该 sudog 准备就绪;
- 调用 runtime.goparkunlock 将当前的 Goroutine 陷入沉睡等待唤醒;
- 被调度器唤醒后会执行一些收尾工作,将一些属性置零并且释放 runtime.sudog 结构体;
函数在最后会返回true,表示已经向channel发送数据
小结
我们在这里可以简单梳理和总结一下使用 ch <- i 表达式向 Channel 发送数据时遇到的几种情况:
- 如果当前 Channel 的 recvq 上存在已经被阻塞的 Goroutine,那么会直接将数据发送给当前 Goroutine 并将其设置成下一个运行的 Goroutine;
- 如果 Channel 存在缓冲区并且其中还有空闲的容量,我们会直接将数据存储到缓冲区 sendx 所在的位置上;
- 如果不满足上面的两种情况,会创建一个 runtime.sudog 结构并将其加入 Channel 的 sendq 队列中,当前 Goroutine 也会陷入阻塞等待其他的协程从 Channel 接收数据;
发送数据的过程中包含几个会触发 Goroutine 调度的时机:
- 发送数据时发现 Channel 上存在等待接收数据的 Goroutine,立刻设置处理器的 runnext 属性,但是并不会立刻触发调度;
- 发送数据时并没有找到接收方并且缓冲区已经满了,这时会将自己加入 Channel 的 sendq 队列并调用 runtime.goparkunlock 触发 Goroutine 的调度让出处理器的使用权;
接收数据
- 当存在等待的发送者时,通过 runtime.recv 从阻塞的发送者或者缓冲区中获取数据;
- 当缓冲区存在数据时,从 Channel 的缓冲区中接收数据;
- 当缓冲区中不存在数据时,等待其他 Goroutine 向 Channel 发送数据;
小结
我们梳理一下从 Channel 中接收数据时可能会发生的五种情况:
- 如果 Channel 为空,那么会直接调用 runtime.gopark 挂起当前 Goroutine;
- 如果 Channel 已经关闭并且缓冲区没有任何数据,runtime.chanrecv 会直接返回;
- 如果 Channel 的 sendq 队列中存在挂起的 Goroutine,会将 recvx 索引所在的数据拷贝到接收变量所在的内存空间上并将 sendq 队列中 Goroutine 的数据拷贝到缓冲区;
- 如果 Channel 的缓冲区中包含数据,那么直接读取 recvx 索引对应的数据;
- 在默认情况下会挂起当前的 Goroutine,将 runtime.sudog 结构加入 recvq 队列并陷入休眠等待调度器的唤醒;
我们总结一下从 Channel 接收数据时,会触发 Goroutine 调度的两个时机:
- 当 Channel 为空时;
- 当缓冲区中不存在数据并且也不存在数据的发送者时;
Interface 接口的底层实现
Go语言使用runtime.iface表示一组方法的接口, 使用runtime.eface表示不包含任何方法的接口 interface{}, 两种接口虽然都使用 interface 声明,但是由于后者在 Go 语言中很常见,所以在实现时使用了特殊的类型。
interface{} 类型不是任意类型。如果我们将类型转换成了 interface{} 类型,变量在运行期间的类型也会发生变化,获取变量类型时会得到 interface{}。
package main
func main() {
type Test struct{}
v := Test{}
Print(v)
}
func Print(v interface{}) {
println(v)
}
上述函数不接受任意类型的参数,只接受 interface{} 类型的值,在调用 Print 函数时会对参数 v 进行类型转换,将原来的 Test 类型转换成 interface{} 类型,本节会在后面介绍类型转换的实现原理。
指针和接口
在 Go 语言中同时使用指针和接口时会发生一些让人困惑的问题,接口在定义一组方法时没有对实现的接收者做限制,所以我们会看到某个类型实现接口的两种方式, 一种是值接受者,另一种是指针接受者
结构提类型和指针类型是不同的,同样实现虽然两种类型不同,我们也不能同时实现两种相同的接口,Go 语言的编译器会在结构体类型和指针类型都实现一个方法时报错 “method redeclared”。
| 结构体实现接口 | 结构体指针实现接口 | |
|---|---|---|
| 结构体初始化变量 | 通过 | 不通过 |
| 结构体指针初始化变量 | 通过 | 通过 |
四种中只有使用指针实现接口,使用结构体初始化变量无法通过编译,其他的三种情况都可以正常执行。当实现接口的类型和初始化变量时返回的类型时相同时,代码通过编译是理所应当的:
- 方法接受者和初始化类型都是结构体;
- 方法接受者和初始化类型都是结构体指针;
而剩下的两种方式为什么一种能够通过编译,另一种无法通过编译呢?我们先来看一下能够通过编译的情况,即方法的接受者是结构体,而初始化的变量是结构体指针
type Cat struct{}
func (c Cat) Quack() {
fmt.Println("meow")
}
func main() {
var c Duck = &Cat{}
c.Quack()
}
作为指针的 &Cat{} 变量能够隐式地获取到指向的结构体,所以能在结构体上调用 Walk 和 Quack 方法。我们可以将这里的调用理解成 C 语言中的 d->Walk() 和 d->Speak(),它们都会先获取指向的结构体再执行对应的方法。
但是如果我们将上述代码中方法的接受者和初始化的类型进行交换,代码就无法通过编译了:
type Duck interface {
Quack()
}
type Cat struct{}
func (c *Cat) Quack() {
fmt.Println("meow")
}
func main() {
var c Duck = Cat{}
c.Quack()
}
$ go build interface.go
./interface.go:20:6: cannot use Cat literal (type Cat) as type Duck in assignment:
Cat does not implement Duck (Quack method has pointer receiver)
编译器会提醒我们:Cat 类型没有实现 Duck 接口,Quack 方法的接受者是指针。这两个报错对于刚刚接触 Go 语言的开发者比较难以理解,如果我们想要搞清楚这个问题,首先要知道 Go 语言在传递参数时都是传值的。
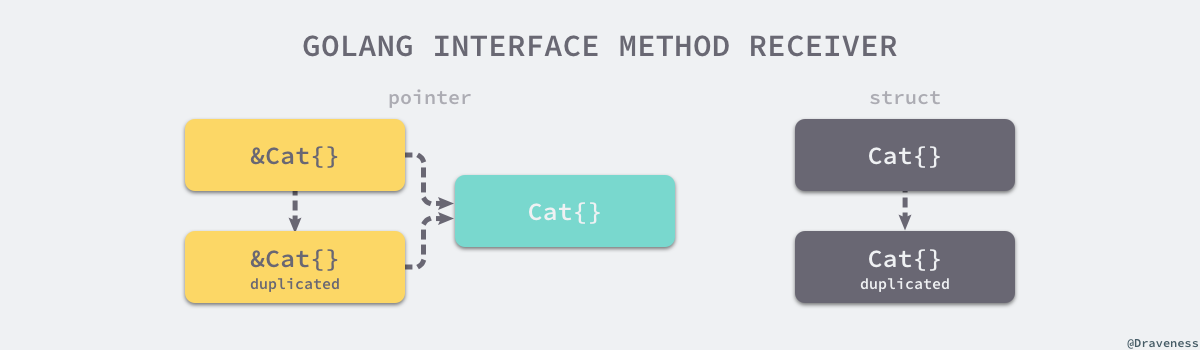
如上图所示,无论上述代码中初始化的变量 c 是 Cat{} 还是 &Cat{},使用 c.Quack() 调用方法时都会发生值拷贝:
如上图左侧,对于 &Cat{} 来说,这意味着拷贝一个新的 &Cat{} 指针,这个指针与原来的指针指向一个相同并且唯一的结构体,所以编译器可以隐式的对变量解引用(dereference)获取指针指向的结构体;
如上图右侧,对于 Cat{} 来说,这意味着 Quack 方法会接受一个全新的 Cat{},因为方法的参数是 *Cat,编译器不会无中生有创建一个新的指针;即使编译器可以创建新指针,这个指针指向的也不是最初调用该方法的结构体;
上面的分析解释了指针类型的现象,当我们使用指针实现接口时,只有指针类型的变量才会实现该接口;当我们使用结构体实现接口时,指针类型和结构体类型都会实现该接口。当然这并不意味着我们应该一律使用结构体实现接口,这个问题在实际工程中也没那么重要,在这里我们只想解释现象背后的原因。
nil 和 non-nil #
我们可以通过一个例子理解Go 语言的接口类型不是任意类型这一句话,下面的代码在 main 函数中初始化了一个 *TestStruct 类型的变量,由于指针的零值是 nil,所以变量 s 在初始化之后也是 nil:
package main
type TestStruct struct{}
func NilOrNot(v interface{}) bool {
return v == nil
}
func main() {
var s *TestStruct
fmt.Println(s == nil) // #=> true
fmt.Println(NilOrNot(s)) // #=> false
}
$ go run main.go
true
false
调用 NilOrNot 函数时发生了隐式的类型转换,除了向方法传入参数之外,变量的赋值也会触发隐式类型转换。
数据结构
Go 语言根据接口类型是否包含一组方法将接口类型分成了两类:
- 使用 runtime.iface 结构体表示包含方法的接口
- 使用 runtime.eface 结构体表示不包含任何方法的 interface{} 类型;
runtime.eface 结构体在 Go 语言中的定义是这样的:
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}
由于 interface{} 类型不包含任何方法,所以它的结构也相对来说比较简单,只包含指向底层数据和类型的两个指针。从上述结构我们也能推断出 — Go 语言的任意类型都可以转换成 interface{}。
另一个用于表示接口的结构体是 runtime.iface,这个结构体中有指向原始数据的指针 data,不过更重要的是 runtime.itab 类型的 tab 字段。
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer
}
接下来我们将详细分析 Go 语言接口中的这两个类型,即 runtime._type 和 runtime.itab。
runtime._type 是 Go 语言类型的运行时表示。下面是运行时包中的结构体,其中包含了很多类型的元信息,例如:类型的大小、哈希、对齐以及种类等。
type _type struct {
size uintptr // 字段存储了类型占用的内存空间,为内存空间的分配提供信息;
ptrdata uintptr
hash uint32 // 字段能够帮助我们快速确定类型是否相等
tflag tflag
align uint8
fieldAlign uint8
kind uint8
equal func(unsafe.Pointer, unsafe.Pointer) bool // 字段用于判断当前类型的多个对象是否相等,该字段是为了减少 Go 语言二进制包大小从 typeAlg 结构体中迁移过来的;
gcdata *byte
str nameOff
ptrToThis typeOff
}
itab 结构体
runtime.itab 结构体是接口类型的核心组成部分,每一个 runtime.itab 都占 32 字节,我们可以将其看成接口类型和具体类型的组合,它们分别用 inter 和 _type 两个字段表示:
type itab struct { // 32 字节
inter *interfacetype
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr
}
除了 inter 和 _type 两个用于表示类型的字段之外,上述结构体中的另外两个字段也有自己的作用:
- hash 是对 _type.hash 的拷贝,当我们想将 interface 类型转换成具体类型时,可以使用该字段快速判断目标类型和具体类型 runtime._type 是否一致;
- fun 是一个动态大小的数组,它是一个用于动态派发的虚函数表,存储了一组函数指针。虽然该变量被声明成大小固定的数组,但是在使用时会通过原始指针获取其中的数据,所以 fun 数组中保存的元素数量是不确定的;
我们会在类型断言中介绍 hash 字段的使用,在动态派发一节中介绍 fun 数组中存储的函数指针是如何被使用的。
类型转换
既然我们已经了解了接口在运行时的数据结构,接下来会通过几个例子来深入理解接口类型是如何初始化和传递的,本节会介绍在实现接口时使用指针类型和结构体类型的区别。这两种不同的接口实现方式会导致 Go 语言编译器生成不同的汇编代码,进而影响最终的处理过程。
Go同步原句与锁
Go原生支持多协程,当提到并发编程、多线程编程时,往往都离不开锁这一概念。锁是一种并发编程中的同步原语(Synchronization Primitives),它能保证多个 Goroutine 在访问同一片内存时不会出现竞争条件(Race condition)等问题。
Go 语言在 sync 包中提供了用于同步的一些基本原语,包括常见的 sync.Mutex、sync.RWMutex、sync.WaitGroup、sync.Once 和 sync.Cond:
Mutex
Go语言的sync.Mutex由两个字段state 和sema组成,其中 state 表示当前互斥锁的状态,而 sema 是用于控制锁状态的信号量。
type Mutex struct {
state int32
sema uint32
}
上述两个加起来只占 8 字节空间的结构体表示了 Go 语言中的互斥锁。
状态state
互斥锁状态比较复杂,其中最低三位分别表示mutexLocked,mutexWoken和mutexStarving,剩下的位置用来表示当前有多少goroutine在等待互斥锁的释放:
在默认情况下,互斥锁的所有状态位都是 0,int32 中的不同位分别表示了不同的状态:
- mutexLocked — 表示互斥锁的锁定状态;
- mutexWoken — 表示从正常模式被从唤醒;
- mutexStarving — 当前的互斥锁进入饥饿状态;
- waitersCount — 当前互斥锁上等待的 Goroutine 个数;
模式:正常模式和饥饿模式
在正常模式下,锁的等待者会按照先进先出的顺序获取锁。但是刚被唤起的 Goroutine 与新创建的 Goroutine 竞争时,大概率会获取不到锁,为了减少这种情况的出现,一旦 Goroutine 超过 1ms 没有获取到锁,它就会将当前互斥锁切换饥饿模式,防止部分 Goroutine 被『饿死』。
在饥饿模式中,互斥锁会直接交给等待队列最前面的 Goroutine。新的 Goroutine 在该状态下不能获取锁、也不会进入自旋状态,它们只会在队列的末尾等待。如果一个 Goroutine 获得了互斥锁并且它在队列的末尾或者它等待的时间少于 1ms,那么当前的互斥锁就会切换回正常模式。
与饥饿模式相比,正常模式下的互斥锁能够提供更好地性能,饥饿模式的能避免 Goroutine 由于陷入等待无法获取锁而造成的高尾延时。
加锁和解锁
我们在这一节中将分别介绍互斥锁的加锁和解锁过程,它们分别使用 sync.Mutex.Lock 和 sync.Mutex.Unlock 方法。
互斥锁的加锁是靠 sync.Mutex.Lock 完成的,最新的 Go 语言源代码中已经将 sync.Mutex.Lock 方法进行了简化,方法的主干只保留最常见、简单的情况 — 当锁的状态是 0 时,将 mutexLocked 位置成 1
如果互斥锁状态不是1,当前gouroutine就尝试自旋等待锁的释放,该方法是一个非常大的for循环,分成以下几步:
- 判断当前 Goroutine 能否进入自旋;
- 通过自旋等待互斥锁的释放;
- 计算互斥锁的最新状态;
- 更新互斥锁的状态并获取锁;
第一步,判断当前Goroutine能否进入自旋等互斥锁的释放比较严苛:
- 互斥锁只有在普通模式才能进入自旋;
- runtime.sync_runtime_canSpin 需要返回 true:
- 运行在多 CPU 的机器上;
- 当前 Goroutine 为了获取该锁进入自旋的次数小于四次;
- 当前机器上至少存在一个正在运行的处理器 P 并且处理的运行队列为空;
一旦当前 Goroutine 能够进入自旋就会调用runtime.sync_runtime_doSpin 和 runtime.procyield 并执行 30 次的 PAUSE 指令,该指令只会占用 CPU 并消耗 CPU 时间
处理了自旋逻辑后,互斥锁会 根据上下文计算当前互斥锁的最新状态,几个不同的条件分别会更新 state 字段中存储的不同信息 — mutexLocked、mutexStarving、mutexWoken 和 mutexWaiterShift.
计算了新的互斥锁状态之后,会使用 CAS 函数 sync/atomic.CompareAndSwapInt32 更新状态, 如果没有通过CAS获得锁,就会调用 runtime.sync_runtime_SemacquireMutex 通过信号量保证资源不会被两个 Goroutine 获取。runtime.sync_runtime_SemacquireMutex 会在方法中不断尝试获取锁并陷入休眠等待信号量的释放,一旦当前 Goroutine 可以获取信号量,它就会立刻返回,sync.Mutex.Lock 的剩余代码也会继续执行。
- 在正常模式下,这段代码会设置唤醒和饥饿标记、重置迭代次数并重新执行获取锁的循环;
- 在饥饿模式下,当前 Goroutine 会获得互斥锁,如果等待队列中只存在当前 Goroutine,互斥锁还会从饥饿模式中退出;
解锁
互斥锁的解锁过程 sync.Mutex.Unlock 与加锁过程相比就很简单,该过程会先使用 sync/atomic.AddInt32 函数快速解锁,这时会发生下面的两种情况:
- 如果该函数返回的新状态等于 0,当前 Goroutine 就成功解锁了互斥锁;
- 如果该函数返回的新状态不等于 0,这段代码会调用 sync.Mutex.unlockSlow 开始慢速解锁:
sync.Mutex.unlockSlow 会先校验锁状态的合法性 — 如果当前互斥锁已经被解锁过了会直接抛出异常 “sync: unlock of unlocked mutex” 中止当前程序。
RWMutex
读写互斥锁 sync.RWMutex 是细粒度的互斥锁,它不限制资源的并发读,但是读写、写写操作无法并行执行。
| 读 | 写 |
|---|---|
| 读 | Y |
| 写 | N |
常见服务的资源读写比例会非常高,因为大多数的读请求之间不会相互影响,所以我们可以分离读写操作,以此来提高服务的性能。
sync.RWMutex 中总共包含以下 5 个字段:
type RWMutex struct {
w Mutex
writerSem uint32
readerSem uint32
readerCount int32
readerWait int32
}
- w — 复用互斥锁提供的能力;
- writerSem 和 readerSem — 分别用于写等待读和读等待写:
- readerCount 存储了当前正在执行的读操作数量;
- readerWait 表示当写操作被阻塞时等待的读操作个数;
我们会依次分析获取写锁和读锁的实现原理,其中:
- 写操作使用 sync.RWMutex.Lock 和 sync.RWMutex.Unlock 方法;
- 读操作使用 sync.RWMutex.RLock 和 sync.RWMutex.RUnlock 方法;
写锁
当资源的使用者想要获取写锁时,需要调用 sync.RWMutex.Lock 方法:
- 调用结构体持有的 sync.Mutex 结构体的 sync.Mutex.Lock 阻塞后续的写操作;
- 因为互斥锁已经被获取,其他 Goroutine 在获取写锁时会进入自旋或者休眠;
- 调用 sync/atomic.AddInt32 函数阻塞后续的读操作:
- 如果仍然有其他 Goroutine 持有互斥锁的读锁,该 Goroutine 会调用 runtime.sync_runtime_SemacquireMutex 进入休眠状态等待所有读锁所有者执行结束后释放 writerSem 信号量将当前协程唤醒;
写锁的释放会调用 sync.RWMutex.Unlock
与加锁的过程正好相反,写锁的释放分以下几个执行:
- 调用 sync/atomic.AddInt32 函数将 readerCount 变回正数,释放读锁;
- 通过 for 循环释放所有因为获取读锁而陷入等待的 Goroutine:
- 调用 sync.Mutex.Unlock 释放写锁;
获取写锁时会先阻塞写锁的获取,后阻塞读锁的获取,这种策略能够保证读操作不会被连续的写操作『饿死』。
读锁
读锁的加锁方法 sync.RWMutex.RLock 很简单,该方法会通过 sync/atomic.AddInt32 将 readerCount 加一:
- 如果该方法返回负数 — 其他 Goroutine 获得了写锁,当前 Goroutine 就会调用 runtime.sync_runtime_SemacquireMutex 陷入休眠等待锁的释放;
- 如果该方法的结果为非负数 — 没有 Goroutine 获得写锁,当前方法会成功返回;
当 Goroutine 想要释放读锁时,会调用如下所示的 sync.RWMutex.RUnlock 方法:
该方法会先减少正在读资源的 readerCount 整数,根据 sync/atomic.AddInt32 的返回值不同会分别进行处理:
- 如果返回值大于等于零 — 读锁直接解锁成功;
- 如果返回值小于零 — 有一个正在执行的写操作,在这时会调用sync.RWMutex.rUnlockSlow 方法;
sync.RWMutex.rUnlockSlow 会减少获取锁的写操作等待的读操作数 readerWait 并在所有读操作都被释放之后触发写操作的信号量 writerSem,该信号量被触发时,调度器就会唤醒尝试获取写锁的 Goroutine。
WaitGroup
sync.WaitGroup 可以等待一组 Goroutine 的返回,一个比较常见的使用场景是批量发出 RPC 或者 HTTP 请求, 我们可以通过 sync.WaitGroup 将原本顺序执行的代码在多个 Goroutine 中并发执行,加快程序处理的速度。
结构体
type WaitGroup struct {
noCopy noCopy
state1 [3]uint32
}
- noCopy — 保证 sync.WaitGroup 不会被开发者通过再赋值的方式拷贝;
- state1 — 存储着状态和信号量;
sync.noCopy 是一个特殊的私有结构体,tools/go/analysis/passes/copylock 包中的分析器会在编译期间检查被拷贝的变量中是否包含 sync.noCopy 或者实现了 Lock 和 Unlock 方法,如果包含该结构体或者实现了对应的方法就会报出以下错误
./prog.go:10:10: assignment copies lock value to yawg: sync.WaitGroup
./prog.go:11:14: call of fmt.Println copies lock value: sync.WaitGroup
./prog.go:11:18: call of fmt.Println copies lock value: sync.WaitGroup
这段代码会因为变量赋值或者调用函数时发生值拷贝导致分析器报错
除了 sync.noCopy 之外,sync.WaitGroup` 结构体中还包含一个总共占用 12 字节的数组,这个数组会存储当前结构体的状态,在 64 位与 32 位的机器上表现也非常不同。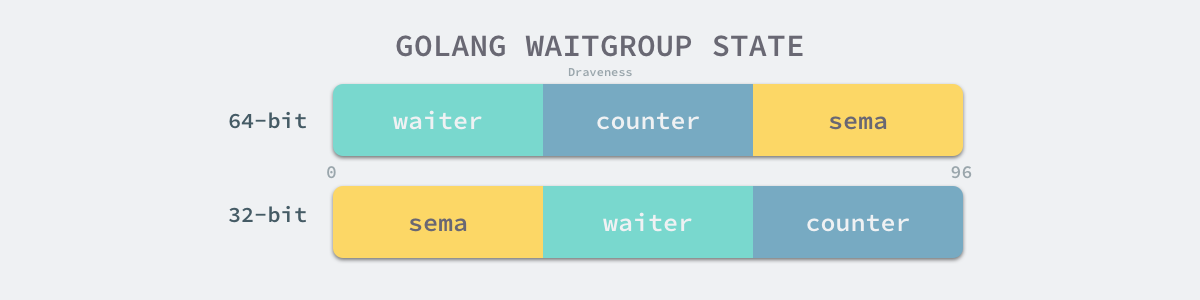
sync.WaitGroup 提供的私有方法 sync.WaitGroup.state 能够帮我们从 state1 字段中取出它的状态和信号量。
sync.WaitGroup 对外暴露了三个方法 — sync.WaitGroup.Add、sync.WaitGroup.Wait 和 sync.WaitGroup.Done。
因为其中的 sync.WaitGroup.Done 只是向 sync.WaitGroup.Add 方法传入了 -1,所以我们重点分析另外两个方法,即 sync.WaitGroup.Add 和 sync.WaitGroup.Wait:
sync.WaitGroup.Add 可以更新 sync.WaitGroup 中的计数器 counter。虽然 sync.WaitGroup.Add 方法传入的参数可以为负数,但是计数器只能是非负数,一旦出现负数就会发生程序崩溃。当调用计数器归零,即所有任务都执行完成时,才会通过 sync.runtime_Semrelease 唤醒处于等待状态的 Goroutine。
sync.WaitGroup 的另一个方法 sync.WaitGroup.Wait 会在计数器大于 0 并且不存在等待的 Goroutine 时,调用 runtime.sync_runtime_Semacquire 陷入睡眠。
当 sync.WaitGroup 的计数器归零时,陷入睡眠状态的 Goroutine 会被唤醒,上述方法也会立刻返回。
通过对 sync.WaitGroup 的分析和研究,我们能够得出以下结论:
- sync.WaitGroup 必须在 sync.WaitGroup.Wait 方法返回之后才能被重新使用;
- sync.WaitGroup.Done 只是对 sync.WaitGroup.Add 方法的简单封装,我们可以向 sync.WaitGroup.Add 方法传入任意负数(需要保证计数器非负)快速将计数器归零以唤醒等待的 Goroutine;
- 可以同时有多个 Goroutine 等待当前 sync.WaitGroup 计数器的归零,这些 Goroutine 会被同时唤醒;
Once
结构体
每一个 sync.Once 结构体中都只包含一个用于标识代码块是否执行过的 done 以及一个互斥锁 sync.Mutex:
type Once struct {
done uint32
m Mutex
}
sync.Once.Do 是 sync.Once 结构体对外唯一暴露的方法,该方法会接收一个入参为空的函数:
- 如果传入的函数已经执行过,会直接返回;
- 如果传入的函数没有执行过,会调用 sync.Once.doSlow 执行传入的函数:
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
- 为当前 Goroutine 获取互斥锁;
- 执行传入的无入参函数;
- 运行延迟函数调用,将成员变量 done 更新成 1;
sync.Once 会通过成员变量 done 确保函数不会执行第二次。
Cond
Go 语言标准库中还包含条件变量 sync.Cond,它可以让一组的 Goroutine 都在满足特定条件时被唤醒。每一个 sync.Cond 结构体在初始化时都需要传入一个互斥锁,我们可以通过下面的例子了解它的使用方法:
var status int64
func main() {
c := sync.NewCond(&sync.Mutex{})
for i := 0; i < 10; i++ {
go listen(c)
}
time.Sleep(1 * time.Second)
go broadcast(c)
ch := make(chan os.Signal, 1)
signal.Notify(ch, os.Interrupt)
<-ch
}
func broadcast(c *sync.Cond) {
c.L.Lock()
atomic.StoreInt64(&status, 1)
c.Broadcast()
c.L.Unlock()
}
func listen(c *sync.Cond) {
c.L.Lock()
for atomic.LoadInt64(&status) != 1 {
c.Wait()
}
fmt.Println("listen")
c.L.Unlock()
}
$ go run main.go
listen
...
listen
sync.Cond 的结构体中包含以下 4 个字段:
type Cond struct {
noCopy noCopy
L Locker
notify notifyList
checker copyChecker
}
- noCopy — 用于保证结构体不会在编译期间拷贝;
- copyChecker — 用于禁止运行期间发生的拷贝;
- L — 用于保护内部的 notify 字段,Locker 接口类型的变量;
- notify — 一个 Goroutine 的链表,它是实现同步机制的核心结构;
type notifyList struct {
wait uint32
notify uint32
lock mutex
head *sudog
tail *sudog
}
sync.Cond 对外暴露的 sync.Cond.Wait 方法会将当前 Goroutine 陷入休眠状态,它的执行过程分成以下两个步骤:
- 调用 runtime.notifyListAdd 将等待计数器加一并解锁;
- 调用 runtime.notifyListWait 等待其他 Goroutine 的唤醒并加锁:
除了将当前 Goroutine 追加到链表的末端之外,我们还会调用 runtime.goparkunlock 将当前 Goroutine 陷入休眠,该函数也是在 Go 语言切换 Goroutine 时经常会使用的方法,它会直接让出当前处理器的使用权并等待调度器的唤醒。
sync.Cond.Signal 和 sync.Cond.Broadcast 就是用来唤醒陷入休眠的 Goroutine 的方法,它们的实现有一些细微的差别:
- sync.Cond.Signal 方法会唤醒队列最前面的 Goroutine;
- sync.Cond.Broadcast 方法会唤醒队列中全部的 Goroutine;
runtime.notifyListNotifyOne 只会从 sync.notifyList 链表中找到满足 sudog.ticket == l.notify 条件的 Goroutine 并通过 runtime.readyWithTime 唤醒:
Goroutine 的唤醒顺序也是按照加入队列的先后顺序,先加入的会先被唤醒,而后加入的可能 Goroutine 需要等待调度器的调度。
在一般情况下,我们都会先调用 sync.Cond.Wait 陷入休眠等待满足期望条件,当满足唤醒条件时,就可以选择使用 sync.Cond.Signal 或者 sync.Cond.Broadcast 唤醒一个或者全部的 Goroutine。
内存分配
- TCMalloc是Thread Cache Malloc的简称,是Go内存管理的起源,Go的内存管理是借鉴了TCMalloc:
内存碎片:随着内存的不断分配申请释放,会有很多碎片,解决:可以将两个连续的未使用的内存块合并
大锁,同一进程的线程共享内存,访问内存需要加锁
内存布局
- page:内存块,一张8kb大小的内存空间,Go与操作系统之间的内存申请和释放都是以page为单位的
- span:内存快,一个或多个连续的page组成一个span
- sizeclass:内存规格,每个span都有一个sizeclass,标记着span中的page如何使用
- object对象:用来存储一个变量数据内存空间,一个span在初始化的时候,会被切割成一堆等大的object,假设object的大小是16b,span大小是8kb,则这个span的page就会切割成8kb/16b=512个object
小于32KB的内存分配
当程序里发生了小于32kb以下的小块内存分配,Go会从一个叫做mcache的本地内存缓存里分配内存,这样的一个内存块叫做span,它是要给程序分配内存时的分配单元.
Go语言调度模型里面,每一个线程M都会绑定一个处理器P,在单一粒度的时间里,只能做多处理一个goroutinen,每个P都会绑定一个上面所说的mcache.当内存需要分配时,当前运行的goroutine会从mcache中查找可用的mspan,从本地mcache里分配内存不需要加锁,这样分配效率更高
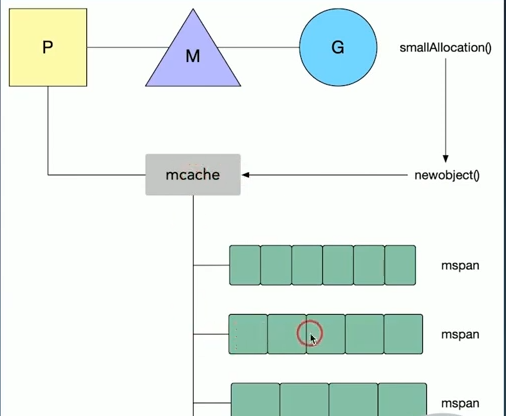
申请内存时会给他们分配一个mspan这样的单元会不会产生浪费,其实mcache持有的一系列mspan并不是固定大小的,而是按照大小从8b到32kb分配了大概67*2类的mspan,每个内存页分为多级固定大小的空闲列表,这有助于减少碎片.
那如果申请内存时mcache里没有空闲对口的sizeclass的span呢?
Go还为每一个mspan的种类维护着一个mcentral.它的作用是为所有的mcache提供切割好的mspan资源,每一个central会持有一种特定大小的mspan,当工作线程的mcache中没有合适大小的mspan时就去mcentral中获取
mcentral被所有的工作线程共同享有,存在多个goroutine竞争的情况因此mcentral需要加锁,mcentral里维护着两个双向链表,nonempty表示里面还有空闲的mspan等待分配,empty表示这个链表里面的mspan都被分配到了mspan里.
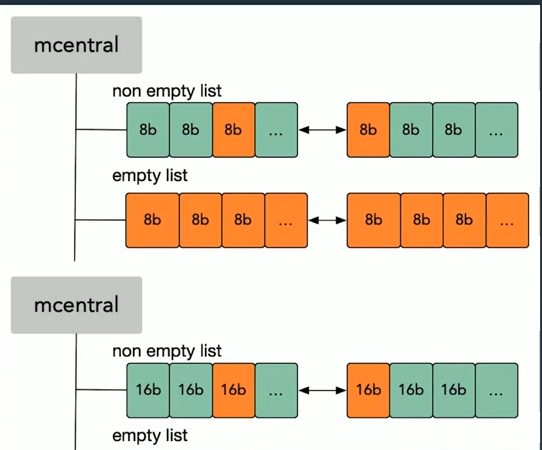
程序申请内存的时候,如果mcache没有空闲的mspan了,那么工作线程就像下图一样去获取和归还mspan的流程:
- 获取加锁,从nonempty链表里面找到一个可用的mspan,并将其从nonempty中删除,将取出的mspan加入到empty链表中,将mspan返回给工作线程,解锁.
- 归还加锁,将mspan从empty中删除,将mspan加入到nonempty链表,解锁
mcentral是sizeclass相同的span会以链表的形式组织在一起,就是指该mspan用来存储哪种大小的对象
如果mcentral如果不够了,还有一个mheap申请,而如果mheap没有资源了, mheap会向操作系统申请新内存,mheap主要用于大对象的分配以及管理未分割的mspan,用于给mcentral切割成小对象.
mheap中含有所有规格的mcentral所以当一个mcache从mcentral申请mspan时,只需要在独立的mcentral中使用锁,并不会影响申请其他规格的mspan
所有mcentral的集合是存放于mheap中的,mheap里的arena区域是真正的堆区,运行时会将8kb看作一页,这些内存页中存储了所有在堆上初始化的对象,运行时使用二维的runtime.heapArena数组管理所有内存,每个runtime.heapAreana都会管理64MB的内存,如果arean区域没有足够的空间,会调用runtime.mheap.sysAlloc从操作系统中申请更多的内存.
arena是一个二维数组,其包含4M个区域,最大有4M*64MB = 256TB的虚拟空间
大于32kb内存分配
Go没法使用工作线程的本地缓存mcache和全局中心缓存mcentral上管理超过32kb的内存申请,所以当需要为超过32kb的内存申请时,会直接在堆上分配对应数量的内存页给程序
小于16kb对象的分配
对于小于16字节的对象,Go语言将其划分成了tiny对象,划分tiny对象的主要目的是为了处理极小的字符串和独立的转意变量.对json的基准测试表明,使用tiny对象减少了12%的分配次数和20%的堆大小,tiny对象会被放入class为2的span中.
- 首先查看之前分配的元素中是否还有多余空间
- 如果当前分配大小不够,例如要分配16b大小这时需要查找下一个空闲元素
tiny分配的第一步是尝试利用分配过前一个元素的空间达到节省内存的目的.
总结:
一般小对象直接通过mspan分配内存,大对象直接通过mheap直接分配内存
- Go程序启动时会向操作系统申请一大块内存,由mheap结构构建全局管理
- Go内存管理的基本单元是mspan,每种mspan可以分配特定大小的object
- mcache,mcentral,mheap是Go内存管理的三大组件,mcache管理本地缓存,mcentral提供全局span供mcache使用