最近在公司做监控方面的工作,接触到了Prometheus、Grafana等云服务产品,特地在此记录下来学习到的知识和使用过程
两万字长文带你入门 Prometheus
本文章已录制B站视频
本文首先会简单介绍一下Prometheus是啥,然后会用Go语言写一些程序上报一些接口数据到Prometheus上,接着通过Grafana展示出来,也算简单了解下云原生的知识了。
本文所用到的所有的库/组件会通过Docker来启动,没用Docker也不用害怕,只是个工具入门就可以了,我们本文用到的也只是最简单的部分。
简介
我们先来简单解释一下啥是Prometheus以及它是怎么来的。
我们知道K8S是由Google的Brog系统演变而来的,Prometheus就是受Brog的监控系统Brogmon启发而来。由前Google的工程师开发,2012年创建、2017年发布Prometheus2.0。
Prometheus是新一代云原生监控系统,社区非常活跃,目前已经有超过650位贡献者并且有超过120+第三方集成(K8s、Etcd、Consul、MySQL等等),目标是达成针对长期趋势分析、告警、数据可视化的目的。
优势:
已于管理,核心只有一个二进制文件,不存在任何第三方依赖。唯一需要的就是本地磁盘,不会有潜在级联故障的风险。Prometheus是一个时序数据库,基于Pull模型的架构方式,可以在任何地方(本地电脑、开发环境、测试环境)搭建我们的监控系统。对于一些复杂情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
数据可以通过Pull的方式获取(例如可以在你的服务下开放一个提供数据端口供Prometheus不断拉取获得),也可以通过Prometheus提供的Pushgateway由我们的应用程序提供推送数据到Pushgateway,接着Pushgateway再推送到Prometheus获得。
采集到的数据指标(metric)保存在内置的时间序列数据库中(TSDB),所有的样本出了基本的指标名称之外,还包含描述样本的标签label:
http_request_status{code='200',content_path='/api/path', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
http_request_status{code='200',content_path='/api/path2', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
每一条时间序列都是由指标名称(Metrics Name)和一系列标签(Labels)组成,每条时间序列按照时间的先后顺序存储一系列的样本值。标签的维度可能来源于我们需要监控的对象,比如我们需要监控某个接口的错误码,那么我们就可以用这样的标签code='1001','endpoint'='/api/hello'。
内置了强大的PromQL语言可以实现对采集指标的查询、聚合,同时也可以应用到数据可视化(Grafana)以及告警中,通过PromQL可以回答以下问题:
- 在过去一段时间中95%应用延迟时间的分布范围?
- 预测在4小时后,磁盘空间占用大致会是什么情况?
- CPU占用率前5位的服务有哪些?(过滤)
环境准备
Prometheus Server
Prometheus 其实就是我们上述所说的最简单的二进制文件,但我们选择通过Docker来启动,首先我们需要准备我们的prometheus.yaml配置文件,放到~/data/prometheus/prometheus.yaml:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
- job_name: 'pushgateway'
static_configs:
- targets: ['host.docker.internal:9092']
labels:
instance: pushgateway
- job_name: 'node'
static_configs:
- targets: ['host.docker.internal:9100']
这里我们只需要了解global和scrape_configs配置,global是全局配置,例如:
global下配置scrape_interval: 15s,意思是抓取间隔是15s一次scrape_configs下的配置是具体的抓取数据的任务,job_name: 名称,targets: 抓取目标地址
提示
由于我们的Prometheus程序是通过Docker启动的,所以想访问我们我们的jobpushgateway和node本机的端口程序需要通过host.docker.internal...意思是我们的pushgateway和node俩任务的数据源不是通过Docker启动的,而是通过我本机来启动的
将这个文件放入~/data/prometheus/prometheus.yaml就可以了(你可以随便放,只要Docker启动prometheus的时候路径对得上就OK),接着我们就通过Docker启动Prometheus:
docker run -it \
-p 9090:9090 \
-v /Users/$YOURHOME/data/prometheus/prometheus.yaml:/etc/prometheus/prometheus.yml \
prom/prometheus \
如果没问题,打开localhost:9090就可以看到界面了
Pushgateway
当我们想采集我们的应用程序的数据时直接上报Prometheus是不可以的,但是我们应用程序的数据可以上报给Pushgateway,然后Prometheus可以从Pushgateway抓取数据,四舍五入等于我们的应用程序上报数据到Prometheus了.......😦
这里下载的时候需要区分系统版本
我的本机(MacOS Arm64)来启动Pushgateway的方式是这样的:
wget https://github.com/prometheus/pushgateway/releases/download/v1.6.2/pushgateway-1.6.2.darwin-arm64.tar.gz
tar xzvf pushgateway-1.6.2.darwin-arm64.tar.gz
mv pushgateway-1.6.2.darwin-arm64/pushgateway /usr/local/bin/
接着启动:
pushgateway --web.listen-address 0.0.0.0:9092
不出意外打开localhost:9092就可以看到对应数据了
相关信息
当然,你也可以通过Docker来启动Pushgateway,但是需要重新写之前的Prometheus配置文件和启动Prometheus Server了
docker pull prom/pushgateway
docker run -d -p 9091:9091 prom/pushgateway
# 收集指标地址需要从 host.docker.internal:9092 改成 172.30.12.167:9092
Node Exporter
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。
因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
从上面的描述中可以看出Exporter可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接内置在监控目标中。只要能够向Prometheus提供标准格式的监控样本数据即可。
这里为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/获取最新的node exporter版本的二进制包。
wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.darwin-amd64.tar.gz
tar -xzf node_exporter-1.6.1.darwin-amd64.tar.gz
cd node_exporter-1.6.1.darwin-amd64
cp node_exporter-1.6.1.darwin-amd64/node_exporter /usr/local/bin/
./node_exporter
启动成功后,可以看到以下输出:
INFO[0000] Listening on :9100 source="node_exporter.go:76"
打开http://localhost:9100/metrics,可以看到当前node exporter获取到的当前主机的所有监控数据,如下所示:
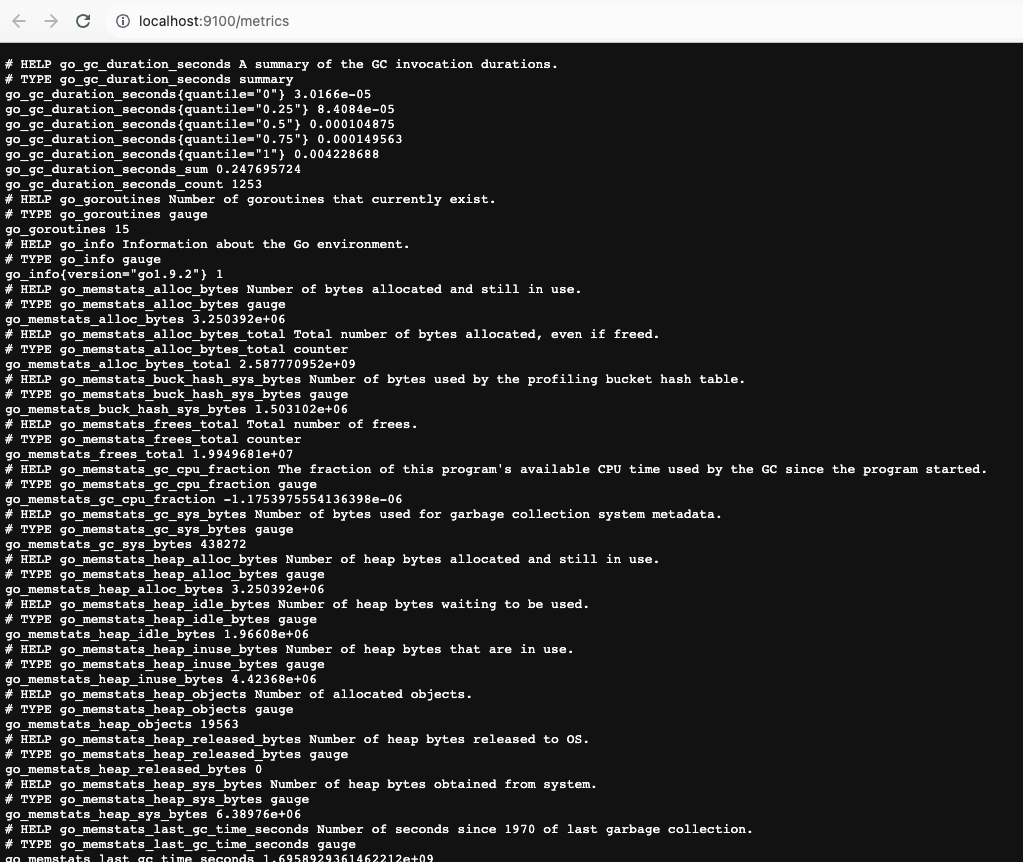
你会发现每一个监控指标之前都会有一段类似于如下形式的信息:
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 375209.421875
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125
其中HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。
在上面的例子中node_cpu的注释表明当前指标是cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是计数器(counter),与该指标的实际含义一致。
又例如node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge),与指标反映的实际含义一致。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
- node_boot_time:系统启动时间
- node_cpu:系统CPU使用量
- nodedisk*:磁盘IO
- nodefilesystem*:文件系统用量
- node_load1:系统负载
- nodememeory*:内存使用量
- nodenetwork*:网络带宽
- node_time:当前系统时间
- go_*:node exporter中go相关指标
- process_*:node exporter自身进程相关运行指标
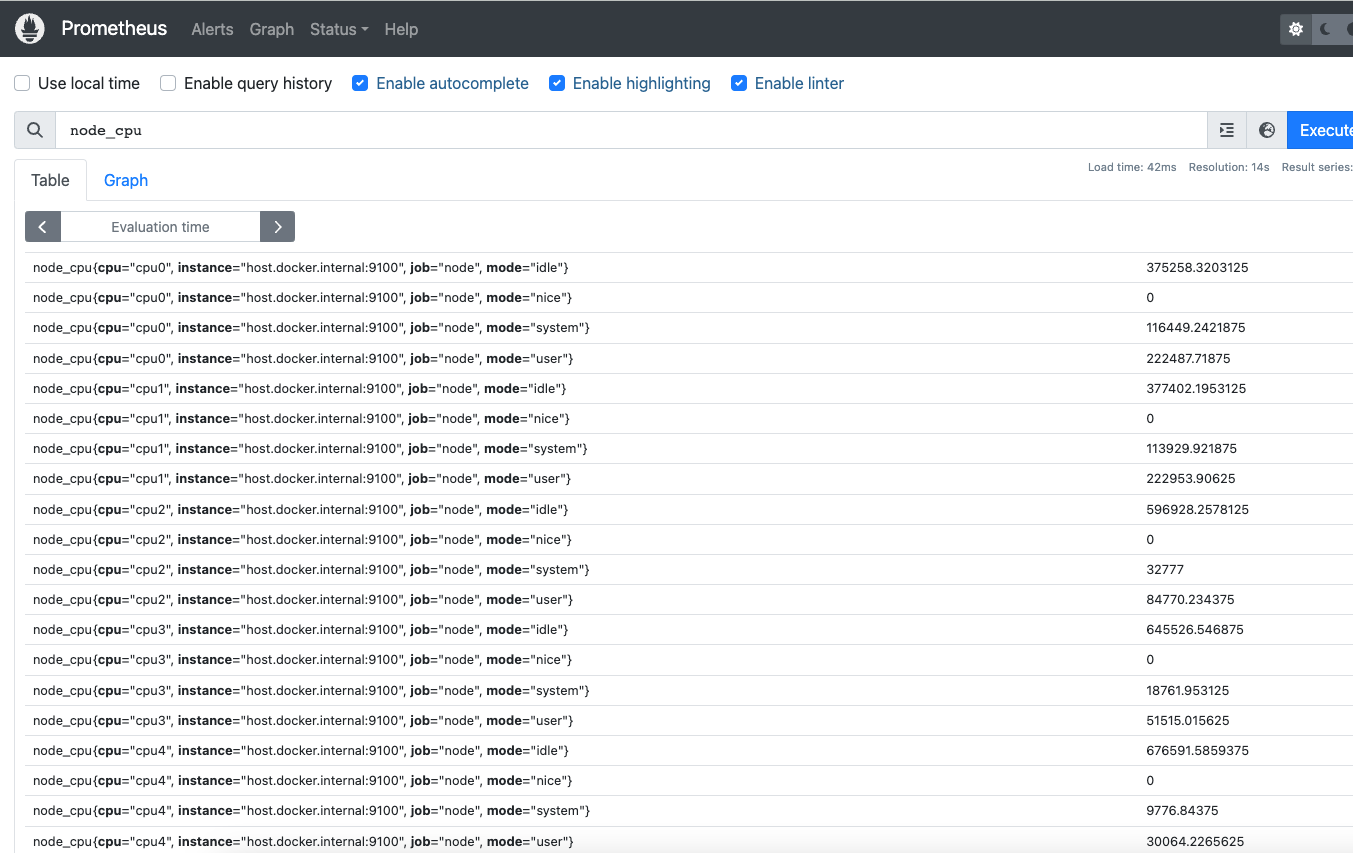
由于我们上面的的prometheus.yaml已经启动并且抓取了9100端口的数据,所以访问localhost:9090是可以找到这些数据的:
Grafana
提示
Grafana可以在教程后面需要时再开启
docker run -d -p 3000:3000 --name=grafana grafana/grafana-enterprise
访问http://localhost:3000就可以进入到Grafana的界面中,默认情况下使用账户账号:admin、密码:admin进行登录。
在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件等主要流程:
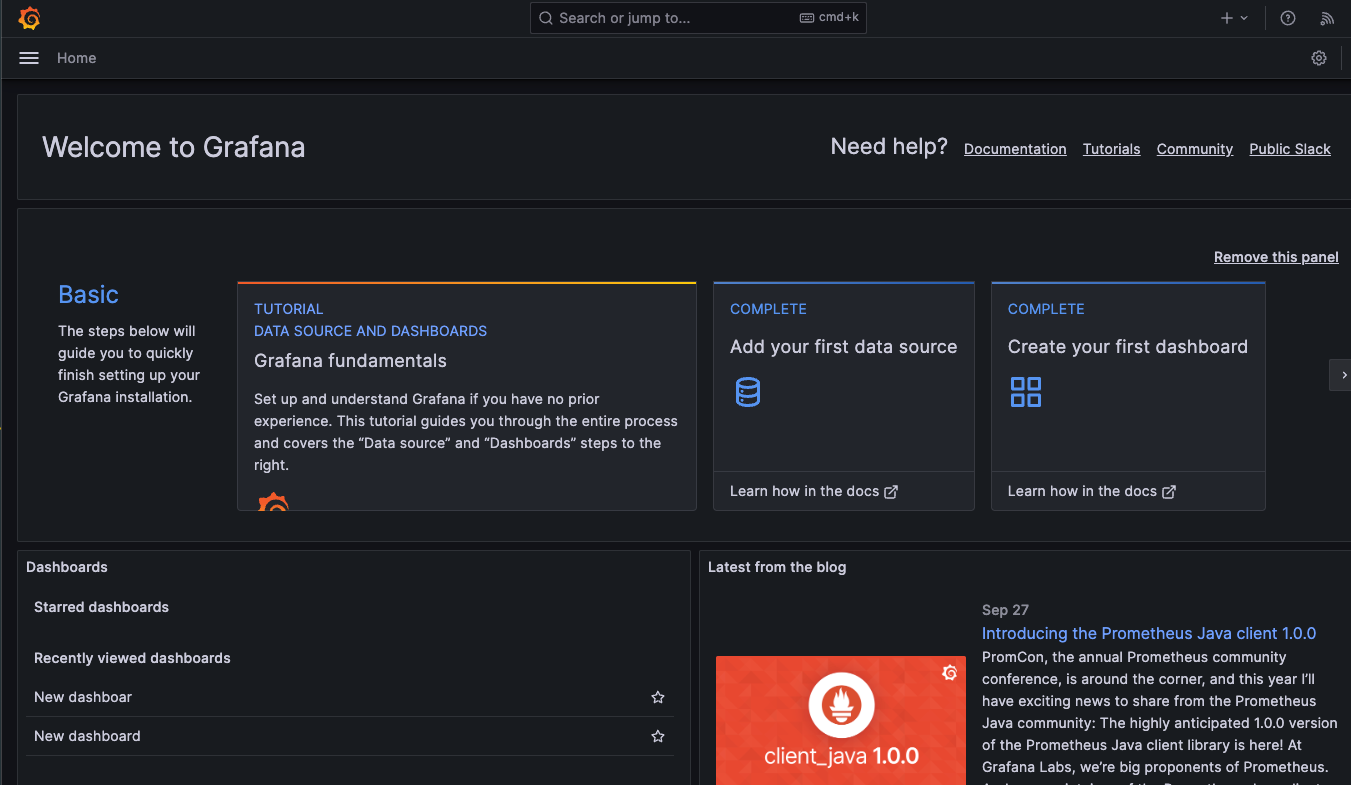
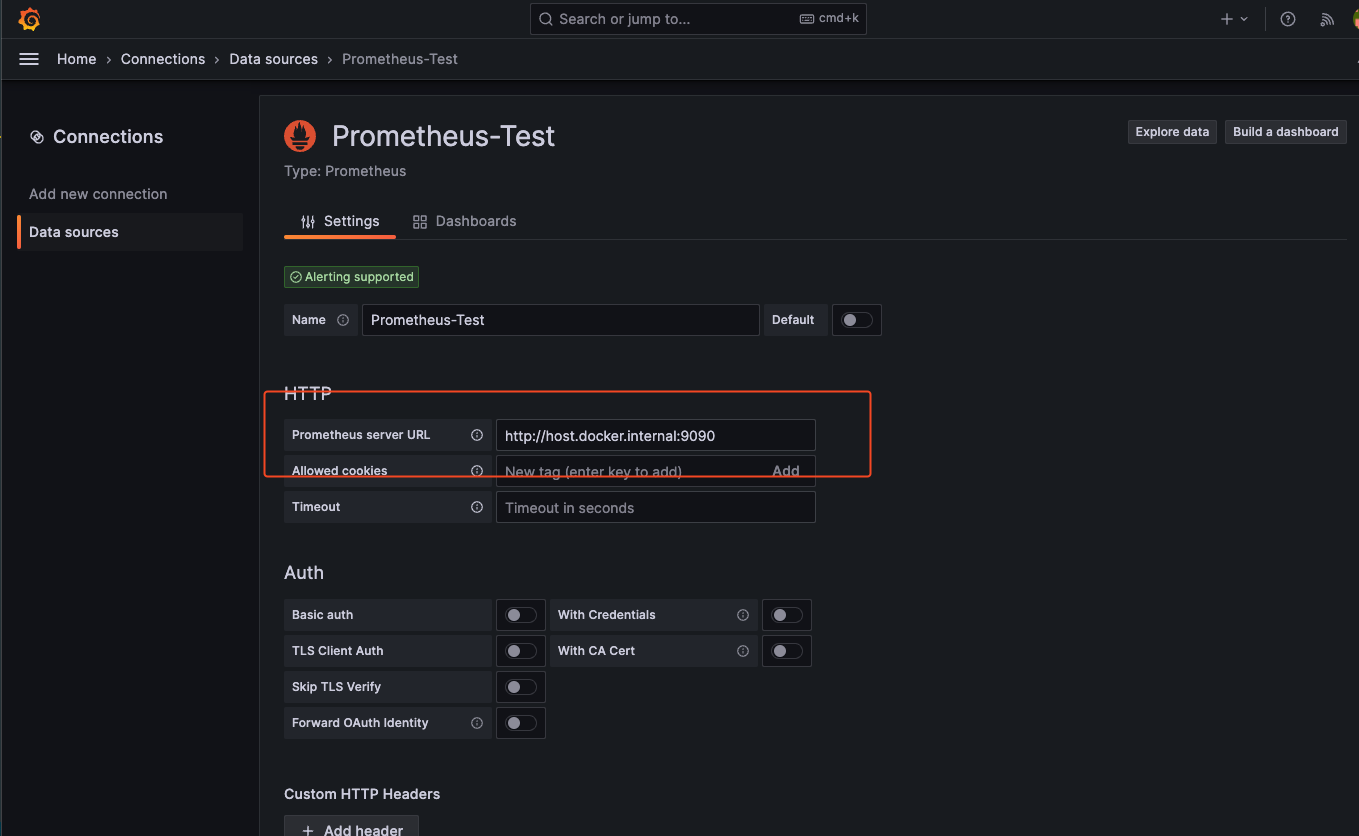
导入 Prometheus 的数据源,注意地址为: http://host.docker.internal:9090:
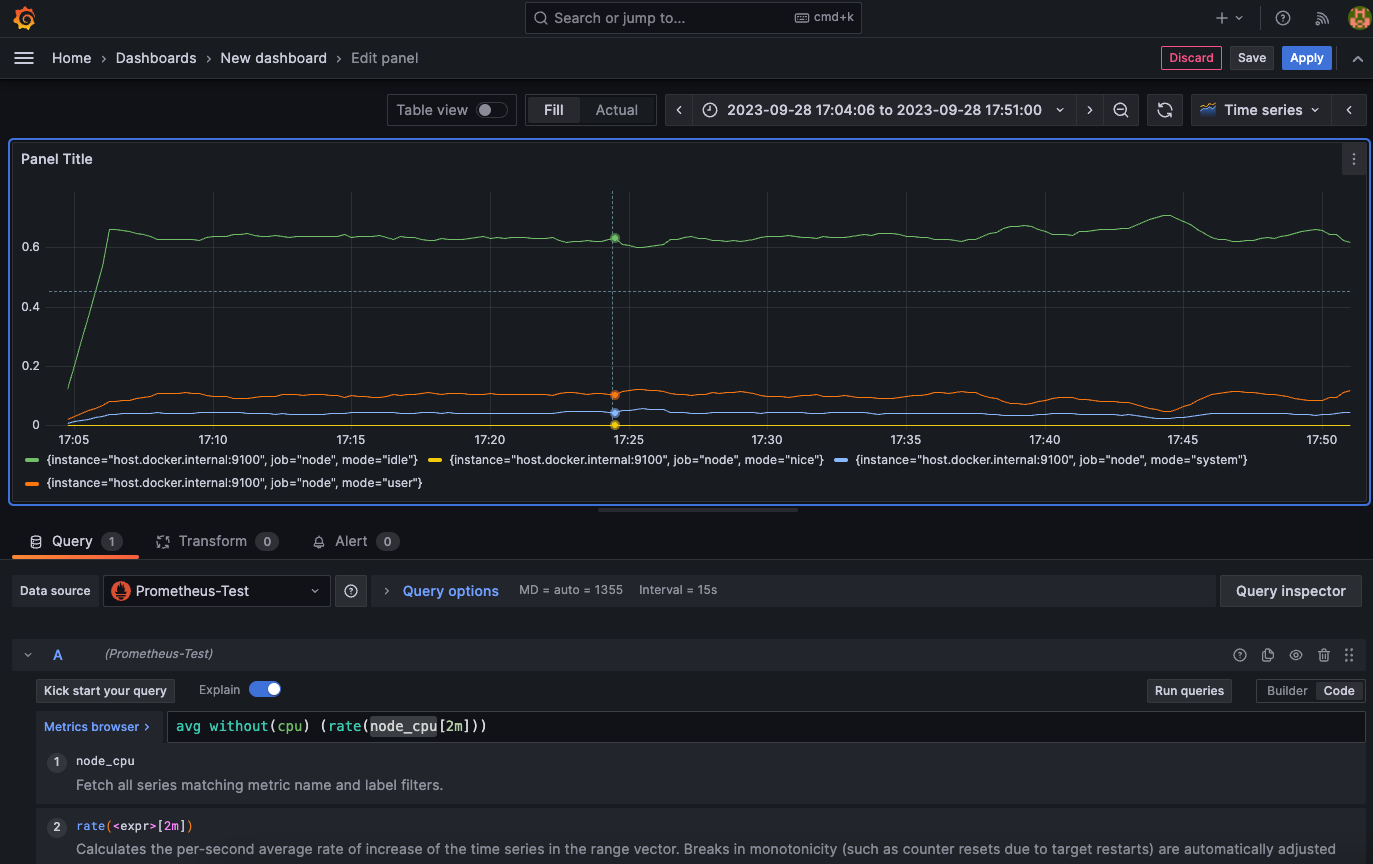
然后就可以启动并且保存指标了:
avg without(cpu) (rate(node_cpu[2m]))
下面我们来了解一下Promethes的四种数据类型
四种数据类型
Prometheus的数据类型有四种:
- Counter:只增不减的计数器
- Gauge:可增可减的仪表盘
- Histogram 直方图 数据分布情况
- Summary 摘要 数据分布情况
Counter:只增不减的计数器
Counter只增不减,除非系统发生重制。常见的监控指标有:http请求总数(统计QPS),cpu使用率,都是Counter类型的监控指标,一般定义Counter类型指标时推荐使用_total作为后缀
例如通过rate函数获取HTTP请求量的增长率:
提示
rate(http_requests_total[5m])
PromQL中直接内置了rate(v range-vector)函数,rate函数可以直接计算区间向量v在时间窗口内平均增长速率。
换句话说上面的PromQL可以替换成 increase(http_request_total[5m]) / 300也就是在5分钟的总请求次数/300秒
查询当前系统中,访问量前10的HTTP地址:
提示
topk(10, http_requests_total)
Gauge:可增可减的仪表盘
与Counter不同,Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
通过Gauge指标,用户可以直接查看系统的当前状态:
node_memory_MemFree
对于Gauge类型的监控指标,通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况。例如,计算CPU温度在两个小时内的差异:
提示
delta(cpu_temp_celsius{host="zeus"}[2h])
还可以使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测。例如,预测系统磁盘空间在4个小时之后的剩余情况:
提示
predict_linear(node_filesystem_free{job="node"}[1h], 4 * 3600)
使用Histogram和Summary分析数据分布情况
大多数情况下我们通常倾向于某些量化指标的平均值,比如CPU平均值,页面平均响应时间。但这样的平均值弊端也很明显,例如一个接口的响应时间大多数情况下都在100毫秒以内,但就是有个别请求需要10s,这回导致某些接口的响应时间远远超过平均数,这种现象叫做肥尾效应。
为了区分是平均的慢还是肥尾的慢,最简单的方式就是按照请求延迟的范围进行分组。
例如,统计延迟在010ms之间的请求数有多少而1020ms之间的请求数又有多少。
通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过Histogram和Summary类型的监控指标,我们可以快速了解监控样本的分布情况。
例如,指标prometheus_tsdb_wal_fsync_duration_seconds的指标类型为Summary。 它记录了Prometheus Server中wal_fsync处理的处理时间,通过访问Prometheus Server的/metrics地址,可以获取到以下监控样本数据:
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Prometheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
在Prometheus Server自身返回的样本数据中,我们还能找到类型为Histogram的监控指标prometheus_tsdb_compaction_chunk_range_bucket。
# HELP prometheus_tsdb_compaction_chunk_range Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range histogram
prometheus_tsdb_compaction_chunk_range_bucket{le="100"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="6400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="25600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="102400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="409600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1.6384e+06"} 260
prometheus_tsdb_compaction_chunk_range_bucket{le="6.5536e+06"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="2.62144e+07"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="+Inf"} 780
prometheus_tsdb_compaction_chunk_range_sum 1.1540798e+09
prometheus_tsdb_compaction_chunk_range_count 780
与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签le进行定义。
同时对于Histogram的指标,我们还可以通过histogram_quantile()函数计算出其值的分位数。不同在于Histogram通过histogram_quantile函数是在服务器端计算的分位数。 而Sumamry的分位数则是直接在客户端计算完成。
因此对于分位数的计算而言,Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。反之对于客户端而言Histogram消耗的资源更少。在选择这两种方式时用户应该按照自己的实际场景进行选择。
上报数据的方式
上报数据有两种一种是通过pull的方式,prometheus自动从配置文件的指定源去拉取数据,另一种是从我们的应用程序上报到pushgateway,然后从pushgateway推送数据:
Go语言监控数据上报
下面我来通过具体的go程序来演示一下:
相关信息
具体的数据展示环节需要配置相应的环境,grafana、prometheus、pushgateway。
下面我通过Go语言来展示两种上报数据的类型:
首先是通过pull模式,prometheus自动从配置文件的指定源去拉取数据,我们只需要给prometheus提供源源不断的数据源:
package main
import (
"log"
"github.com/gin-gonic/gin"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func main() {
r := gin.Default()
r.GET("/metrics", func(c *gin.Context) {
handler := promhttp.Handler()
handler.ServeHTTP(c.Writer, c.Request)
})
err := r.Run(":8081")
if err != nil {
log.Fatalln(err)
}
}
我们上面这段程序的意思是在8081端口提供数据,然后在我们的prometheus.yaml配置中新增对应的配置项来pull抓取8081端口/metrics的数据:
- job_name: go-gin-test
static_configs:
- targets: ['host.docker.internal:8081']
于是你可以看到的结果是:
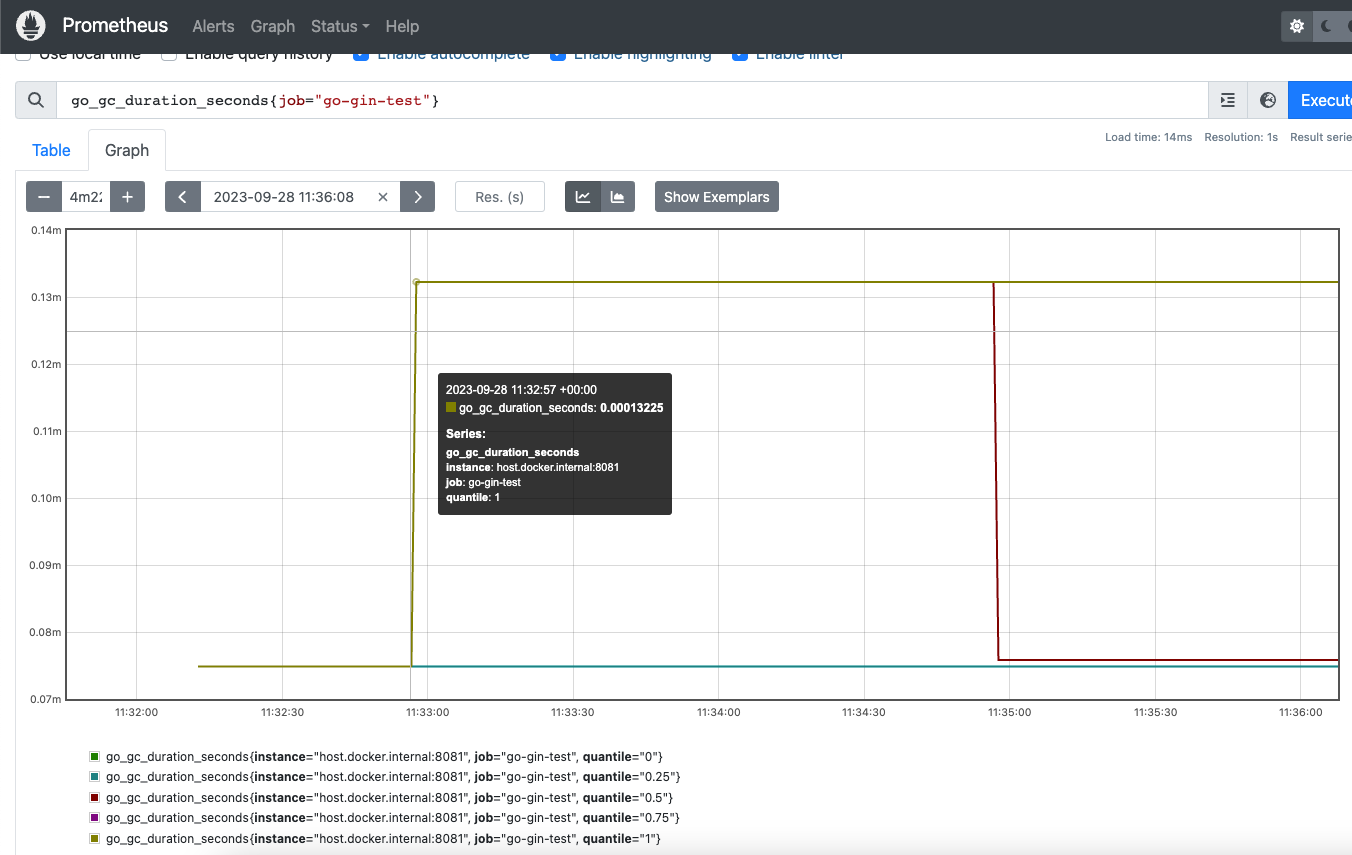
这是我们提供对应的端口,然后prometheus程序不断去拉取数据的方式。
还有另一种就是通过讲数据推送push到pushgateway,然后prometheus去pushgateway拉取数据的方式,下面我通过Go语言的实例来分别讲解推送数据的方式,以及顺便讲解prometheus,Counter、Gauge、Histogram数据类型的常见应用。
接口QPS监控
我们要查看接口的QPS的话,我们的应用程序需要上报什么数据呢?其实很简单,只需要在程序里定义一个计数器,在接口处,每次进来一个请求以后加1之后即可,为了更加合理的使用prometheus, 我们在程序中定义一个Counter计数器变量, 不同的接口根据不同的label区分. 代码如下:
package main
import (
"fmt"
"log"
"net/http"
"time"
"github.com/gin-gonic/gin"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/push"
)
const (
Port = ":8082"
PrometheusUrl = "http://127.0.0.1:9092"
PrometheusJob = "gin_test_prometheus_qps"
PrometheusNamespace = "gin_test_data"
EndpointsDataSubsystem = "endpoints"
)
var (
pusher *push.Pusher
endpointsQPSMonitor = prometheus.NewCounterVec(
prometheus.CounterOpts{
Namespace: PrometheusNamespace,
Subsystem: EndpointsDataSubsystem,
Name: "QPS_statistic",
Help: "统计QPS数据",
}, []string{EndpointsDataSubsystem},
)
)
func init() {
pusher = push.New(PrometheusUrl, PrometheusJob)
prometheus.MustRegister(
endpointsQPSMonitor,
)
pusher.Collector(endpointsQPSMonitor)
}
func HandleEndpointQps() gin.HandlerFunc {
return func(c *gin.Context) {
endpoint := c.Request.URL.Path
fmt.Println(endpoint)
// Counter .Add() 指标加1
endpointsQPSMonitor.With(prometheus.Labels{EndpointsDataSubsystem: endpoint}).Inc()
c.Next()
}
}
func main() {
r := gin.New()
go func() {
// 每15秒上报一次数据
for range time.Tick(15 * time.Second) {
if err := pusher.
Add(); err != nil {
log.Println(err)
}
log.Println("push ")
}
}()
go func() {
var req func(endpoint string)
req = func(endpoint string) {
defer func() {
if r := recover(); r != nil {
log.Println(r)
}
}()
_, err := http.Get(fmt.Sprintf("http://localhost%s%s", Port, endpoint))
if err != nil {
panic(err)
}
}
twoSecondTicker := time.NewTicker(time.Second * 2)
halfSecondTicker := time.NewTicker(time.Second / 2)
for {
select {
case <-halfSecondTicker.C:
req("/world")
case <-twoSecondTicker.C:
req("/hello")
}
}
}()
r.Use(HandleEndpointQps())
r.GET("/hello", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"Hello": "World",
})
})
r.GET("/world", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"World": "Hello",
})
})
r.Run(Port)
}
我们这段代码的大意是定义了两个接口/hello和/world,然后启动一个goroutine去每15秒给prometheus pushgateway上报一次数据,然后在另一个goroutine去分别访问这两个接口访问,访问这两个接口的时候,会通过我们的gin中间件HandleEndpointQps,对接口的endpoint增加,于是在prometheus上呈现最终的结果这样的。
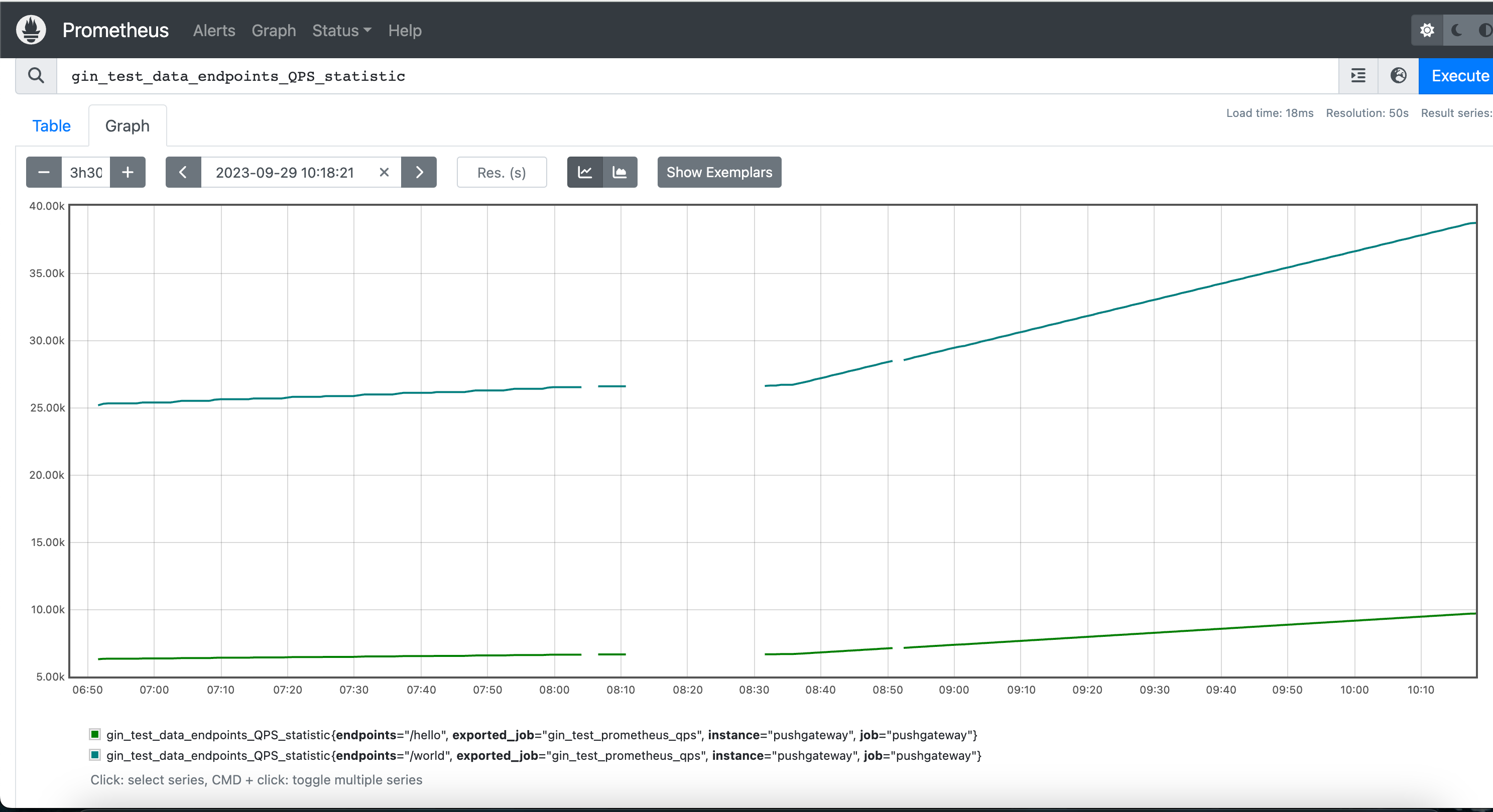
嗯...这就是最终的总counter的数据,如果想看增长率的话,需要使用promQL去查询比如rate(gin_test_data_endpoints_QPS_statistic[1m]).
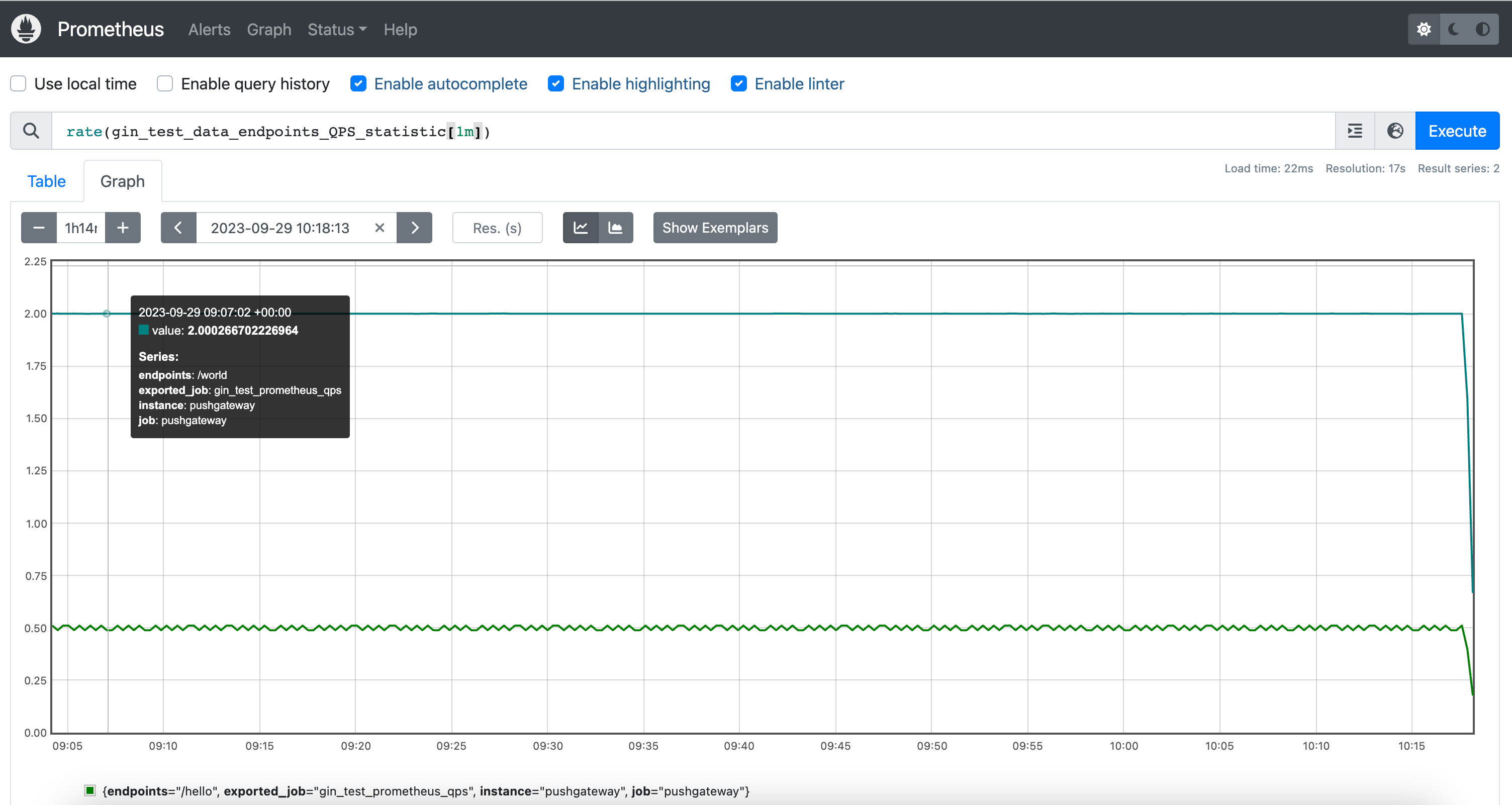
这样的数据就可以当作是统计每个间隔为1m内的QPS,/world接口是2(即每秒访问到2次),/hello接口是0.5。
接口耗时监控
这里我介绍一下监控接口的耗时监控, 那么如何监控接口的响应时间, 这要从Prometheus支持的数据类型说起. 这里还是用部署服务来作为说明,
对于接口监控耗时就不能用平均耗时来作为目标了,因为正常情况下接口耗时平均都很少例如是1ms,但是偶尔有几段情况下某个请求耗时突增到10s了是之前平均耗时的一万倍...那么如果平均一下子,这个突增的接口耗时就没了。所以针对例如接口耗时的请求,我们就不能用prometheus的Counter和Gauge类型了,我们需要用HISTOGRAM和SUMMARY类型。
这两个数据类型非常相似,都非常适用于统计持续一定时间的统计, 比如最常用的就是接口响应时间。
提示
Summary的百分位数(percentile)的计算都是在于客户端上, 而Histogram的计算是在server端来计算的, 所以出于最小化的影响业务, 建议使用Histogram来计算percentile.
这两个类型的详细说明链接在这里使用Histogram和Summary分析数据分布情况
使用这2种数据类型, 方法也很简单, 核心代码逻辑就是定义区间,然后将数据上报出去:
package main
import (
"fmt"
"log"
"math/rand"
"net/http"
"strconv"
"time"
"github.com/gin-gonic/gin"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/push"
)
const (
Port = ":8082"
PrometheusUrl = "http://127.0.0.1:9092"
PrometheusJob = "gin_test_prometheus"
PrometheusNamespace = "gin_test_data"
EndpointsDataSubsystem = "endpoints"
)
var (
pusher *push.Pusher
endpointsLantencyMonitor = prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Namespace: PrometheusNamespace,
Subsystem: EndpointsDataSubsystem,
Name: "lantency_statistic",
Help: "统计耗时数据",
Buckets: []float64{1, 5, 10, 20, 50, 100, 500, 1000, 5000, 10000},
}, []string{EndpointsDataSubsystem},
)
)
func init() {
pusher = push.New(PrometheusUrl, PrometheusJob)
prometheus.MustRegister(
endpointsLantencyMonitor,
)
pusher.Collector(endpointsLantencyMonitor)
}
func HandleEndpointLantency() gin.HandlerFunc {
return func(c *gin.Context) {
endpoint := c.Request.URL.Path
fmt.Println(endpoint)
start := time.Now()
defer func(c *gin.Context) {
lantency := time.Now().Sub(start)
lantencyStr := fmt.Sprintf("%0.3d", lantency.Nanoseconds()/1e6) // 记录ms数据,为小数点后3位
lantencyFloat64, err := strconv.ParseFloat(lantencyStr, 64) //转换成float64类型
if err != nil {
panic(err)
}
fmt.Println(lantencyFloat64)
endpointsLantencyMonitor.With(prometheus.Labels{EndpointsDataSubsystem: endpoint}).Observe(lantencyFloat64)
}(c)
c.Next()
}
}
func main() {
r := gin.New()
go func() {
// 每15秒上报一次数据
for range time.Tick(15 * time.Second) {
if err := pusher.
Add(); err != nil {
log.Println(err)
}
log.Println("push ")
}
}()
go func() {
// 随机1秒内分钟访问一次接口
var req func(endpoint string)
req = func(endpoint string) {
defer func() {
if r := recover(); r != nil {
log.Println(r)
}
}()
_, err := http.Get(fmt.Sprintf("http://localhost%s%s", Port, endpoint))
if err != nil {
panic(err)
}
}
for {
req("/hello")
}
}()
r.Use(HandleEndpointLantency())
var count int
r.GET("/hello", func(c *gin.Context) {
count++
if count%100 == 0 {
suddenSecond := rand.Intn(10) // 0-10s
time.Sleep(time.Duration(suddenSecond) * time.Second)
c.JSON(http.StatusOK, gin.H{
"Hello": "World",
})
return
}
normalSecond := rand.Intn(100) // 0-10ms
time.Sleep(time.Duration(normalSecond) * time.Millisecond)
c.JSON(http.StatusOK, gin.H{
"Hello": "World",
})
})
r.Run(Port)
}
这段代码就是模拟大部分请求耗时在0-100ms之间,但偶尔有秒级别耗时的请求,代码很简单,这里就不过多解释了。
关于prometheus需要注意的是prometheus是数据之间是递增的,比如刚刚我运行的数据如下图所示:
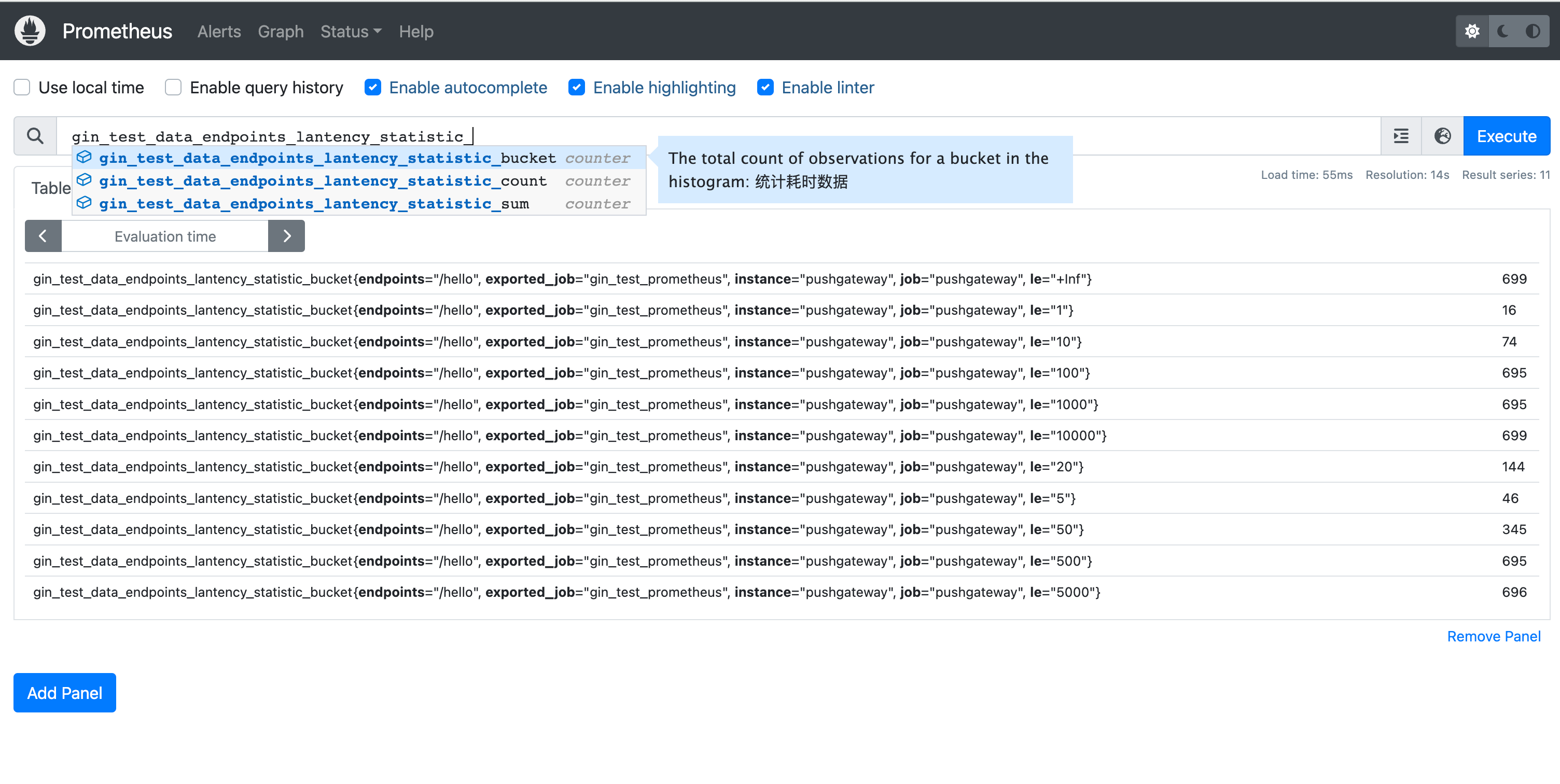
可以看到Histogram类型会自动为我们生成三个数据xxx_bucket(分布桶的数据)、xxx_count(统计请求的总数)、xxx_sum(请求请求的总耗时的和)。
所以我们要看平均耗时就可以通过rate(gin_test_data_endpoints_lantency_statistic_sum[1m]) / rate(gin_test_data_endpoints_lantency_statistic_count[1m])这个公式获得。
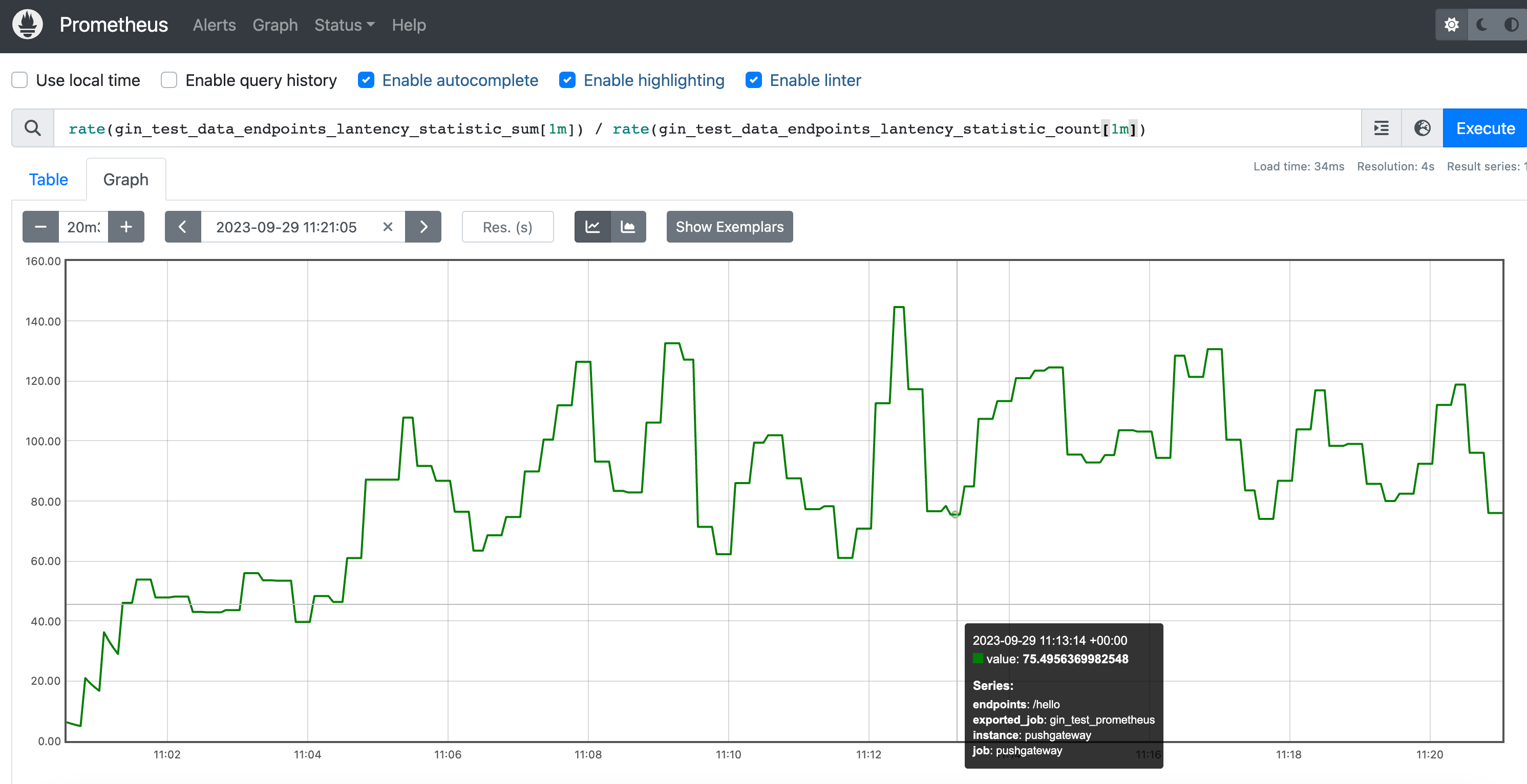
我们再来看看xxx_bucket的数据:
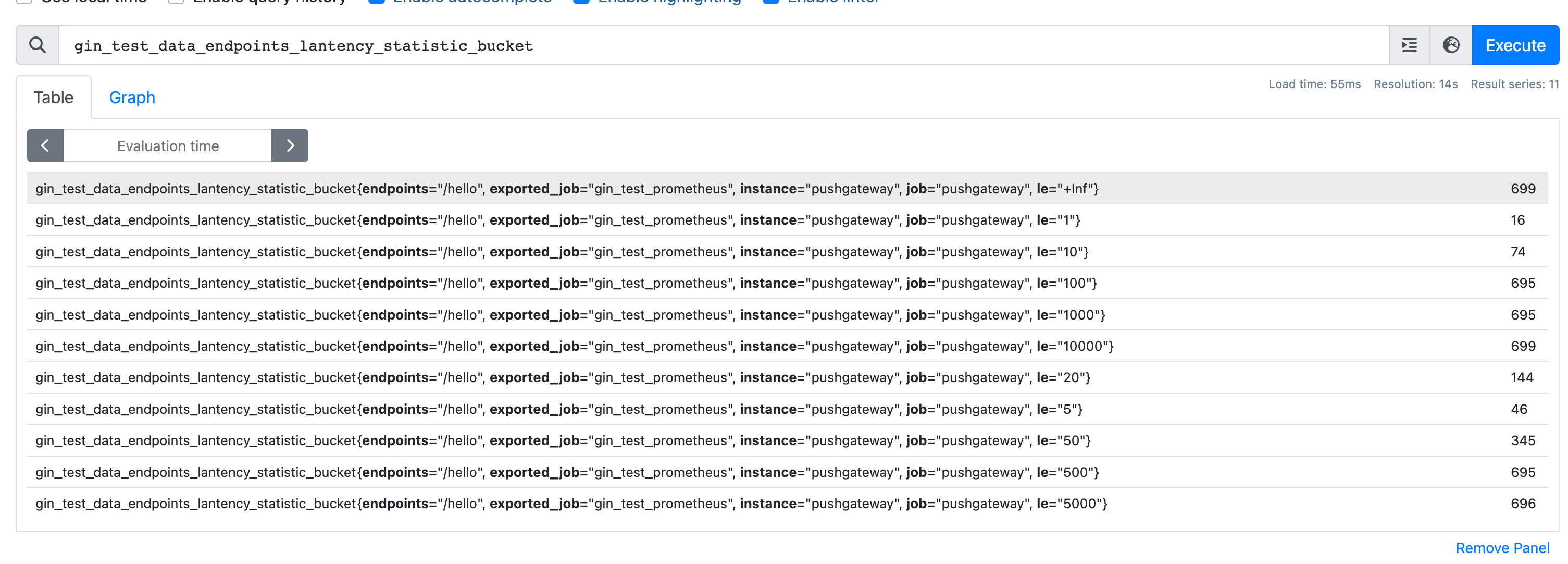
在这个图中每个指标都有一个le的值,指的是小于这个le值的数有多少。
例如
gin_test_data_endpoints_lantency_statistic_bucket{endpoints="/hello", exported_job="gin_test_prometheus", instance="pushgateway", job="pushgateway", le="100"} 695,意思是le小于100的值有695个,le="10000"小于10000的值有699个,所以在100~10000值之间的有4个。
又因为我们程序中定义的单位和统计数据的单位是毫秒(ms),所以上个段落的意思是耗时在0.1ms~10s之间的数据有4次请求。
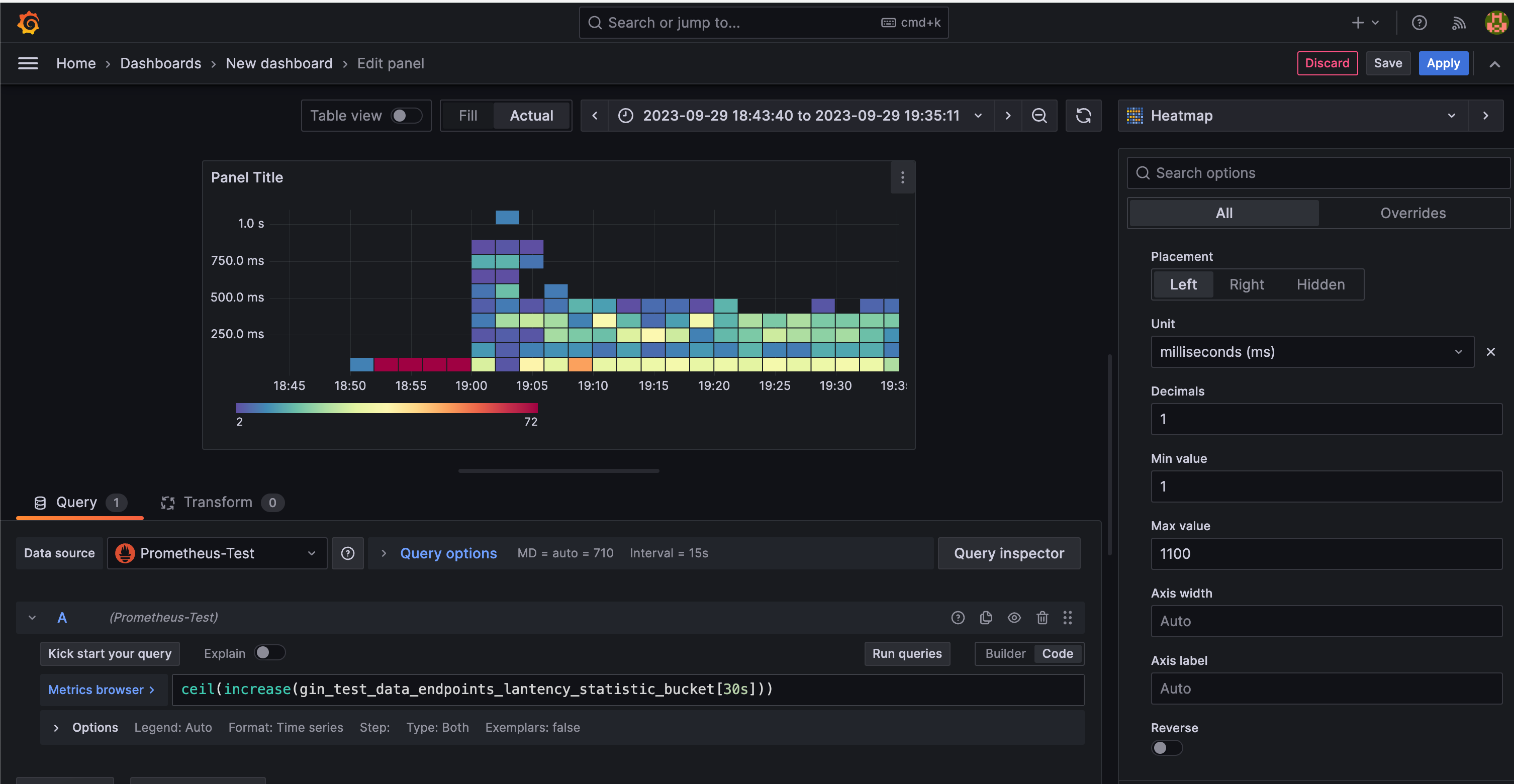
加餐 grafana heatmap图
通过上述图是可以看出统计的耗时分布的,但是grafana有专门的心跳图(heatmap)来统计这样的分布耗时的。
ceil(increase(gin_test_data_endpoints_lantency_statistic_bucket[30s]))这样去统计
- gin_test_data_endpoints_lantency_statistic_bucket是一个Gauge度量值,记录每30秒内各个接口响应时间统计数据的桶值。
- increase是PromQL函数,用于计算一个度量值在指定时间范围内的增加量。
- [30s]后面的时间区间参数表示取本轮桶值与上轮桶值的差值,也就是30秒这个时间窗口内的增加情况。
- ceil是向上取整函数,因为增加值可能是小数,我们需要得到一个整数值。
接口错误码监控
有时候我们需要统计对应接口的错误码,所以label中一般是需要对应的接口endpoint和错误码code,
package main
import (
"bytes"
"encoding/json"
"fmt"
"log"
"net/http"
"time"
"github.com/gin-gonic/gin"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/push"
)
const (
Port = ":8083"
PrometheusUrl = "http://127.0.0.1:9092"
PrometheusJob = "gin_test_prometheus"
PrometheusNamespace = "gin_test_data"
EndpointsDataSubsystem = "endpoints"
ErrCodeDataSubsystem = "code"
)
var (
pusher *push.Pusher
endpointsErrcodeMonitor = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Namespace: PrometheusNamespace,
Subsystem: EndpointsDataSubsystem,
Name: "errcode_statistic",
Help: "统计接口错误码信息数据",
}, []string{EndpointsDataSubsystem, ErrCodeDataSubsystem},
)
)
var (
SUCCESS = NewRespCode(1000, "Success")
ERROR_MYSQL = NewRespCode(2000, "MySQL发生错误")
ERROR_REDIS = NewRespCode(2001, "Redis发生错误")
ERRROR_INTERNAL = NewRespCode(2002, "Internal发生错误")
)
type DataResp struct {
Code int
Msg string
Data any
}
type RespCode struct {
Code int
Msg string
}
func NewRespCode(code int, msg string) RespCode {
return RespCode{
Code: code,
Msg: msg,
}
}
func NewDataResp(respCode RespCode, data any) DataResp {
return DataResp{
Code: respCode.Code,
Msg: respCode.Msg,
Data: data,
}
}
func init() {
pusher = push.New(PrometheusUrl, PrometheusJob)
prometheus.MustRegister(
endpointsErrcodeMonitor,
)
pusher.Collector(endpointsErrcodeMonitor)
}
type Model struct {
gin.ResponseWriter
respBody *bytes.Buffer
}
func newModel(c *gin.Context) *Model {
return &Model{
c.Writer,
bytes.NewBuffer([]byte{}),
}
}
func (s Model) Write(b []byte) (int, error) {
s.respBody.Write(b)
return s.ResponseWriter.Write(b)
}
// 处理错误码的中间件会比较复杂,因为需要处理响应体的信息
// 所以需要通过改写gin的Context的方法来实现在中间件中获取错误体的信息
func HandleEndpointErrcode() gin.HandlerFunc {
return func(c *gin.Context) {
endpoint := c.Request.URL.Path
model := newModel(c)
// 改写gin.Context的Write 让响应体信息在我们的 model.respBody可查
c.Writer = model
defer func(c *gin.Context) {
var resp DataResp
fmt.Println(model.respBody.String())
if err := json.Unmarshal(model.respBody.Bytes(), &resp); err != nil {
log.Println("解析响应体失败: %+v", resp)
panic(err)
}
endpointsErrcodeMonitor.With(prometheus.Labels{EndpointsDataSubsystem: endpoint, ErrCodeDataSubsystem: resp.Msg}).Inc()
}(c)
c.Next()
}
}
func main() {
r := gin.New()
go func() {
// 每15秒上报一次数据
for range time.Tick(15 * time.Second) {
if err := pusher.
Add(); err != nil {
log.Println(err)
}
log.Println("push ")
}
}()
go func() {
// 随机1秒内分钟访问一次接口
var req func(endpoint string)
req = func(endpoint string) {
defer func() {
if r := recover(); r != nil {
log.Println(r)
}
}()
_, err := http.Get(fmt.Sprintf("http://localhost%s%s", Port, endpoint))
if err != nil {
panic(err)
}
}
for {
req("/hello")
time.Sleep(1 * time.Second)
}
}()
r.Use(HandleEndpointErrcode())
var counter int
r.GET("/hello", func(c *gin.Context) {
counter++
if counter%10 == 0 {
c.JSON(http.StatusOK, NewDataResp(ERROR_MYSQL, "123"))
return
}
if counter%2 == 1 {
c.JSON(http.StatusOK, NewDataResp(SUCCESS, "123"))
return
}
if counter%3 == 1 {
c.JSON(http.StatusOK, NewDataResp(ERRROR_INTERNAL, "123"))
return
}
if counter%3 == 2 {
c.JSON(http.StatusOK, NewDataResp(ERROR_REDIS, "123"))
return
}
})
r.Run(Port)
}
这里的代码就不详细说明了,大家有不懂可以尝试问问AI,或者加我的WX询问。
后面这样我们就可以看到我们接口的数据了:
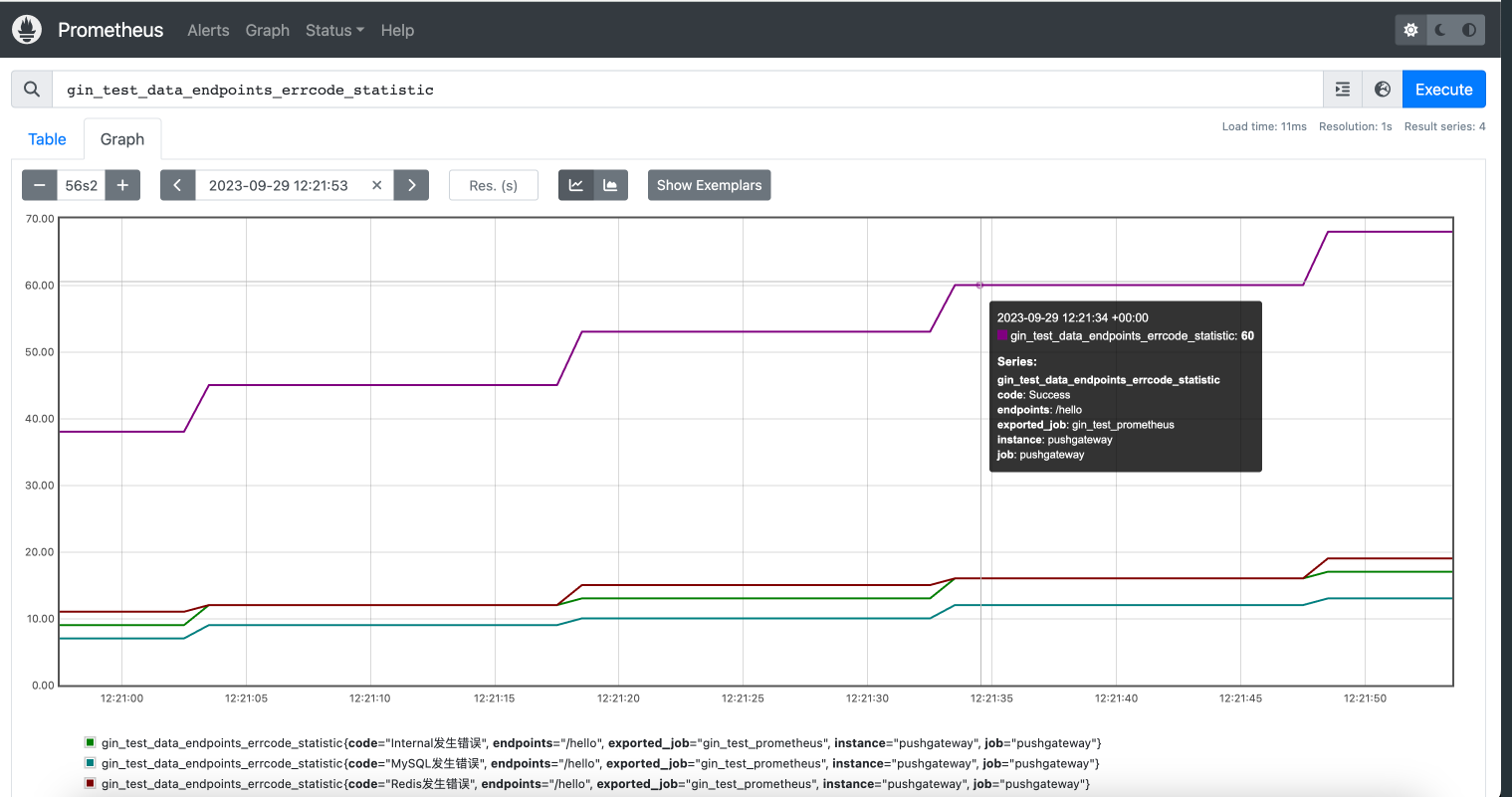
我们这里只统计了/hello的数据,其实也可以有很多别的接口数据,如果我们想查看接口/hello的错误码频率则可以这样:rate(gin_test_data_endpoints_errcode_statistic{endpoints="/hello"}[1m])。
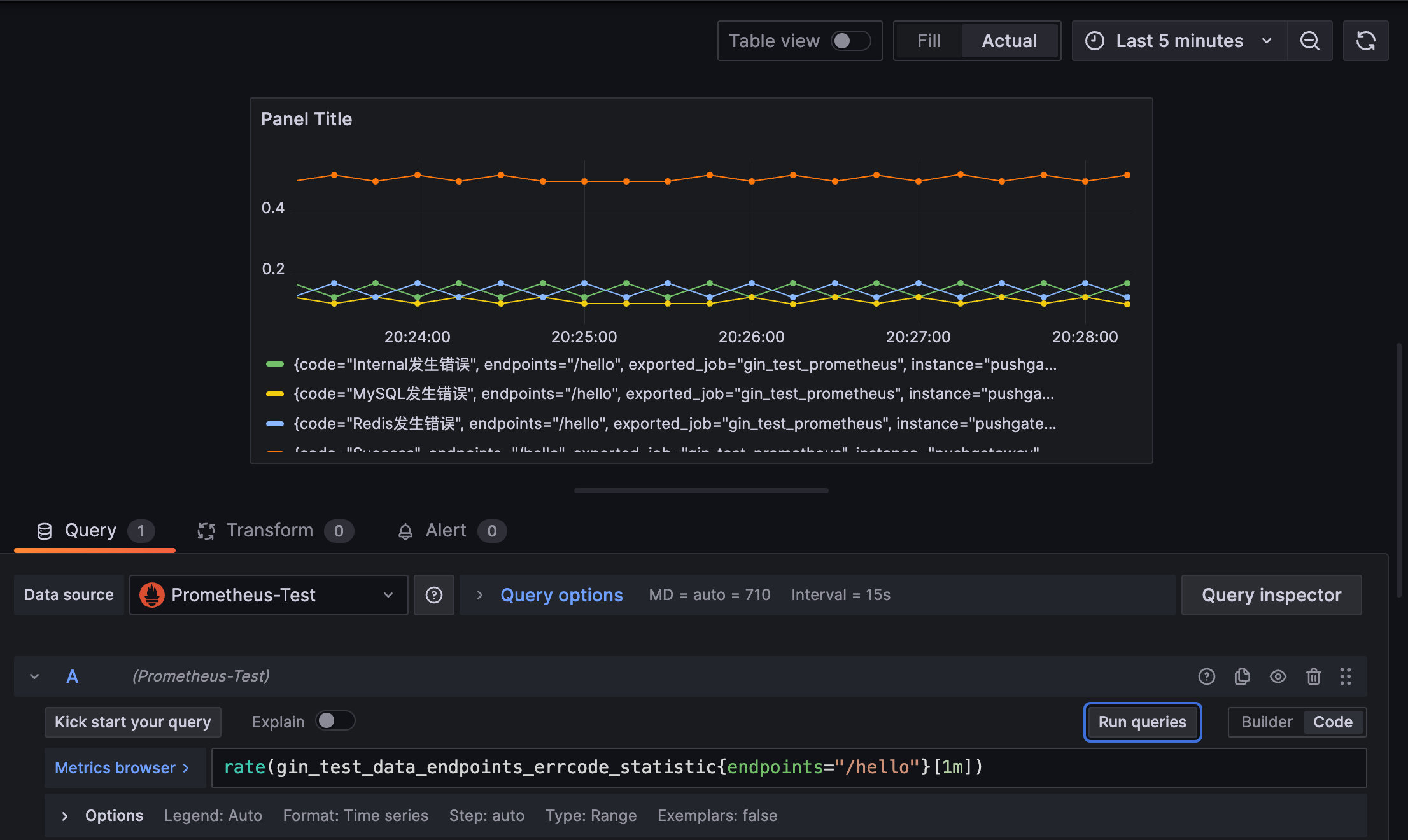
或者基于方法和错误码统计请求错误频率sum by (endpoints, code)(rate(gin_test_data_endpoints_errcode_statistic[1m])):
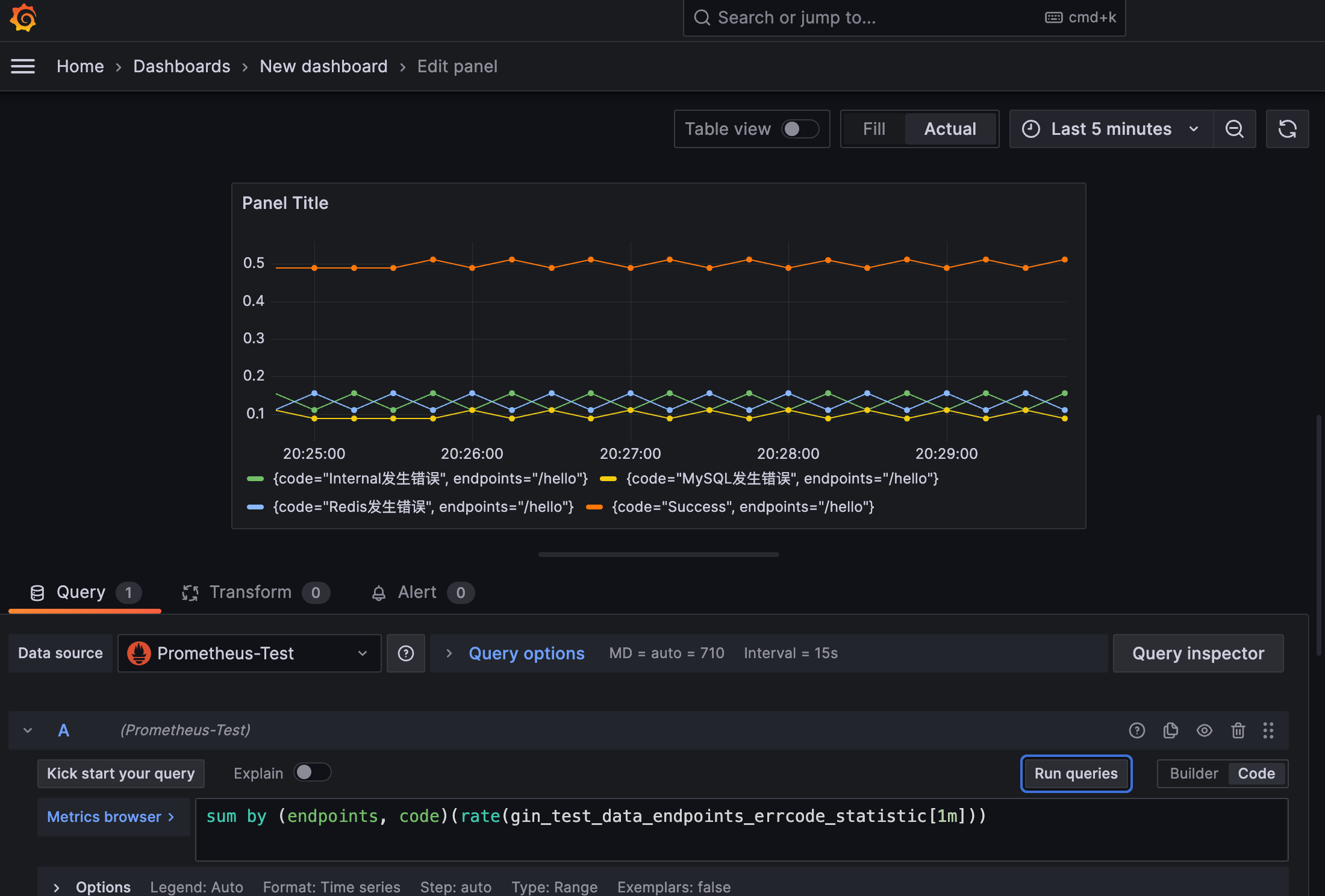
如果我们想统计各方法的接口耗时,使用如下Query语句即可:
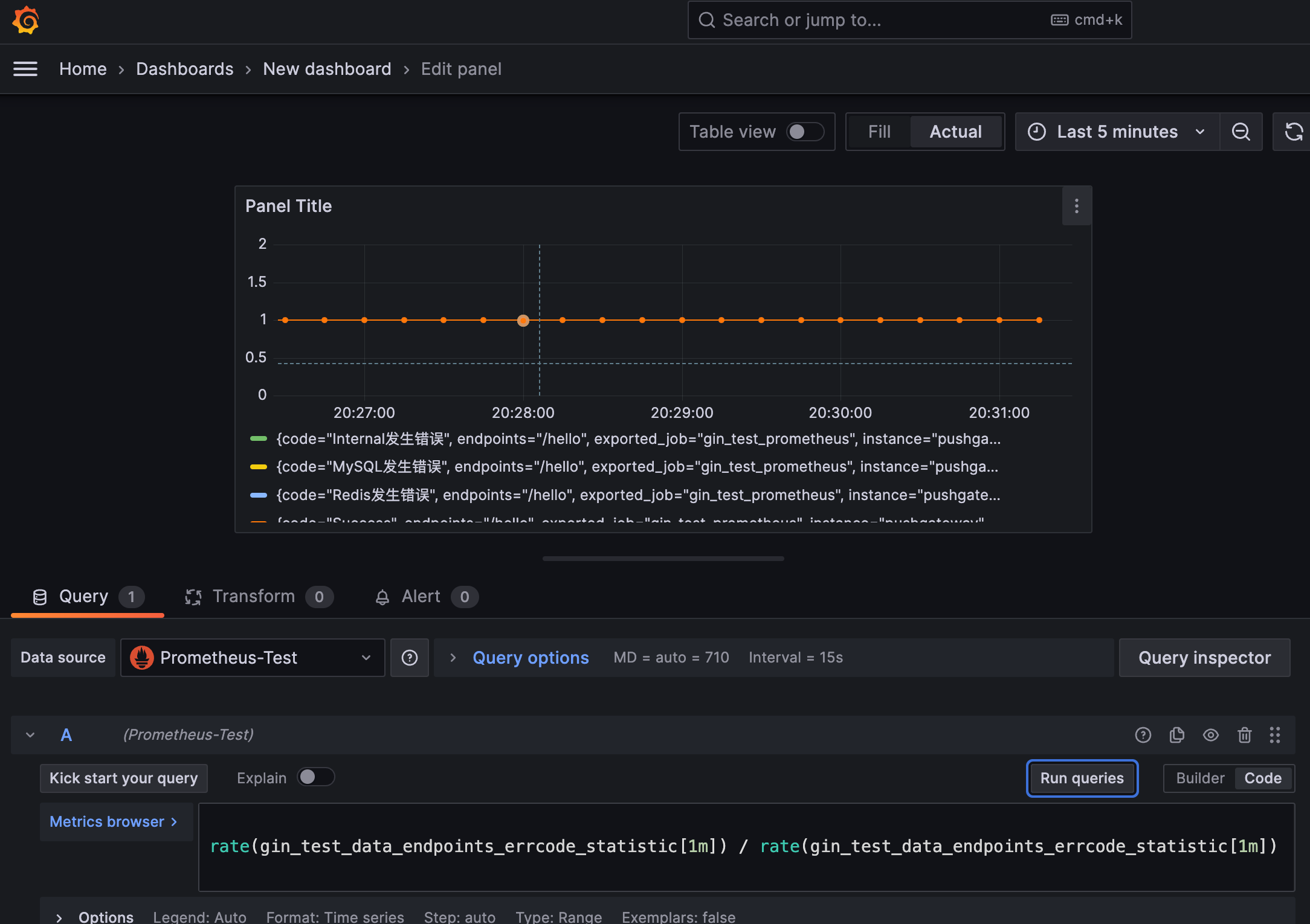
以上图都是只有一个接口的情况下,但实际上真实环境中会有很多个接口。
更多的内建函数这里不展开介绍了。函数使用方法和介绍可以详细参见官方文档中的介绍:https://prometheus.io/docs/querying/functions/。
总结
我们的项目中规模起来了都会对监控都有极强的要求,需要对项目中各组件进行详细监控,如请求次数、接口耗时、接口错误码、节点在线情况等。
业务代码通过与Prometheus集成可以很方便监控我们的业务数据,以上的两万字长文也只是带大家入了个门,后续有更多想法我也会继续更新本文。
本文涉及到的所有代码都在我个人里github仓库里
参考: